📝 Paper Summary
Multimodal RAG
Benchmark datasets
Evaluation methodology
MRAMG-Bench establishes a rigorous evaluation framework for Multimodal Retrieval-Augmented Multimodal Generation, requiring models to autonomously select, order, and interleave images with text to answer complex queries.
Core Problem
Existing RAG methods typically retrieve multimodal data but generate text-only answers, failing to leverage visual information directly in the response.
Why it matters:
- Users often prefer visual answers ('show, don't tell') for tasks like recipe instructions or identifying objects, where text alone is insufficient
- Current benchmarks lack support for evaluating integrated text-image generation, relying on subjective or inconsistent metrics
- MLLMs frequently hallucinate when describing visual content, whereas presenting the original image avoids description errors
Concrete Example:
When asked 'What does a cat look like?', a text description is less effective than a photograph. Similarly, a step-by-step recipe is much clearer when text instructions are interleaved with images of the preparation steps, which current text-only RAG systems cannot produce.
Key Novelty
MRAMG-Bench: A benchmark for generating interleaved text-and-image answers
- Defines the MRAMG task: generating answers that seamlessly integrate text and images retrieved from a multimodal corpus
- Constructs a high-quality human-annotated dataset where models must decide which images to use, how many to use, and where to place them in the text
- Introduces a statistically grounded evaluation framework that assesses both retrieval accuracy and the quality of multimodal generation (ordering, relevance, coherence)
Architecture
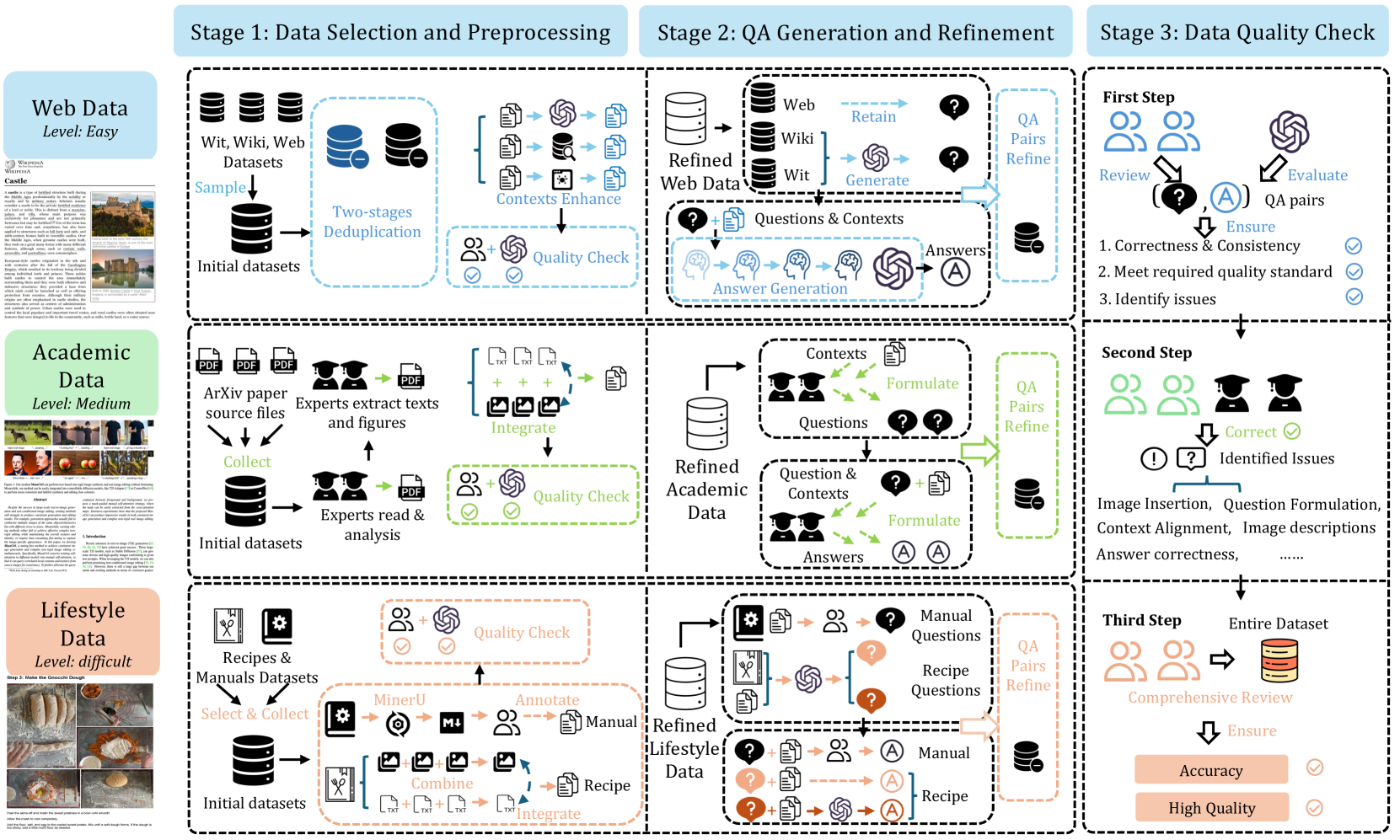
The data construction pipeline for MRAMG-Bench, showing the flow from raw data to the final benchmark
Evaluation Highlights
- Benchmarked 11 popular generative models, revealing significant gaps in current MLLM capabilities for interleaved generation
- Introduced a new dataset comprising 4,800 QA pairs and 14,190 images across diverse domains (Web, Academia, Lifestyle)
- Proposed a unified generation framework allowing both LLMs and MLLMs to perform the MRAMG task via rule-based or model-based image insertion
Breakthrough Assessment
9/10
First comprehensive benchmark specifically for RAG systems that generate multimodal outputs (text + image), addressing a critical gap in current evaluation methodologies.