📝 Paper Summary
Code Generation
Reinforcement Learning (RL) for LLMs
Reasoning Evaluation
Posterior-GRPO improves code generation by training a reasoning-aware reward model on contrastive reasoning pairs and integrating these rewards into RL only when the final code solution is functionally correct.
Core Problem
Current RL for code generation relies on outcome-based rewards (test cases), neglecting the quality of the intermediate reasoning process. Directly supervising reasoning is susceptible to reward hacking.
Why it matters:
- Outcome-only rewards can lead to suboptimal reasoning processes that accidentally pass tests but fail to generalize.
- Neural reward models for reasoning are prone to exploitation (reward hacking), where policies maximize the reward signal without improving code correctness.
- Existing reward models are trained on solutions rather than reasoning processes, creating a semantic gap for code generation tasks.
Concrete Example:
A model solving a perfect square problem might pass basic test cases but fail on negative numbers because its reasoning process didn't consider edge cases. Without process supervision, the model isn't penalized for this reasoning gap until it encounters specific failure cases.
Key Novelty
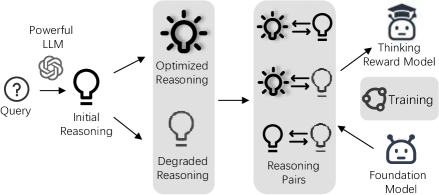
Posterior-GRPO (P-GRPO) & Optimized-Degraded Reward Modeling
- Introduces an 'Optimized-Degraded' method to train reward models: generating high-quality preference pairs by systematically optimizing and degrading reasoning paths along dimensions like factual accuracy and logical rigor.
- Proposes Posterior-GRPO, an RL algorithm that gates 'thinking rewards' based on task success. The reasoning process is only rewarded if the final code passes all test cases, preventing the model from optimizing for high reasoning scores on incorrect code.
Architecture
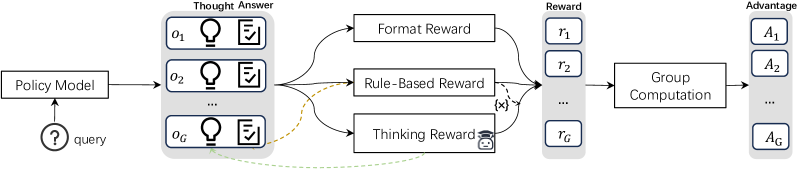
The P-GRPO workflow showing how rewards are computed and gated.
Evaluation Highlights
- P-GRPO with Qwen2.5-Coder-7B-Instruct achieves +13.9% relative improvement over the base model across LiveCodeBench, HumanEval(+), MBPP(+), and BigCodeBench.
- Surpasses RL with outcome-only rewards by 4.5% on average, achieving performance comparable to GPT-4-Turbo.
- On LiveCodeBench specifically, achieves an 18.1% relative improvement over the outcome-only baseline.
Breakthrough Assessment
8/10
Significant advance in process supervision for code generation. Effectively addresses the reward hacking problem in reasoning-based RL with a simple yet powerful posterior gating mechanism. Strong empirical results across multiple benchmarks.