📝 Paper Summary
Graph Generation
Drug Discovery
Discrete Flow Matching
Graph-GRPO aligns discrete graph flow models with task-specific objectives by deriving a differentiable analytical transition probability for RL training and using iterative refinement to explore high-potential regions.
Core Problem
Graph Flow Models (GFMs) rely on non-differentiable Monte Carlo sampling that breaks gradient flows for RL, and their de novo generation often yields invalid graphs with sparse rewards.
Why it matters:
- Drug discovery requires generating molecules with specific, rare properties (e.g., high binding affinity, low toxicity), which generic generative models fail to prioritize
- Existing RL methods for graphs (like GCPN) are hard to integrate with modern flow matching models due to the lack of differentiable transition probabilities
- Inefficient exploration in vast chemical spaces makes finding optimized molecules computationally expensive
Concrete Example:
In the Valsartan SMARTS optimization task, standard generation produces valid molecules that fail to match the specific structural substructure required, while Graph-GRPO's refinement strategy iteratively perturbs and fixes molecules to lock in the desired pattern.
Key Novelty
Analytical Differentiable Transition & Iterative Refinement
- Replaces the standard Monte Carlo sampling in GFMs with a derived analytical formula for transition probabilities, enabling direct gradient-based RL updates without breaking the computation graph
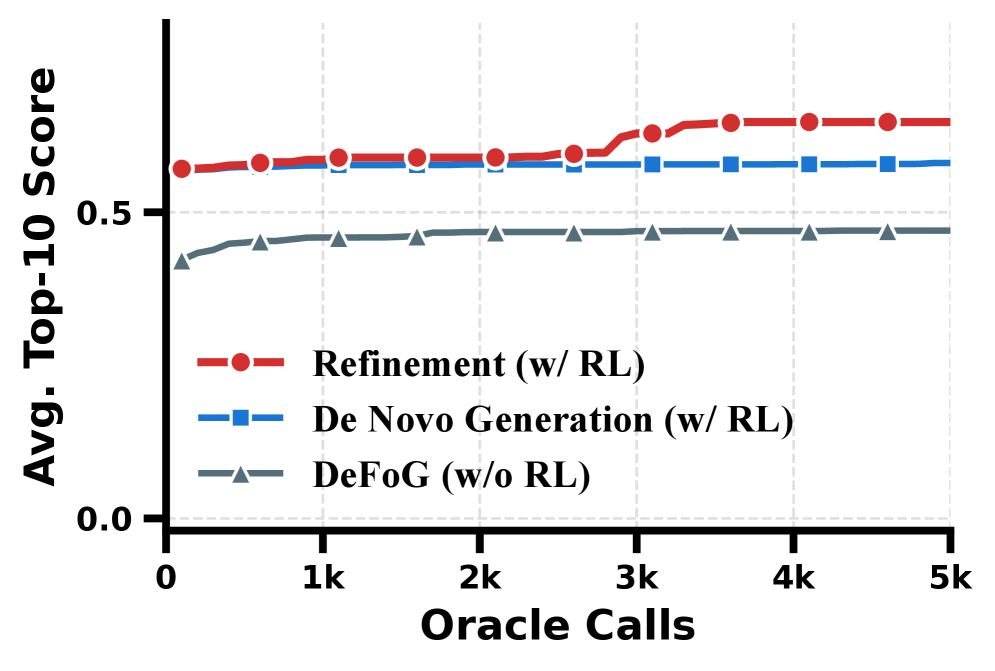
- Introduces a 'refinement' loop where high-reward graphs are slightly corrupted (renoised) and regenerated, allowing the model to perform localized search around promising candidates rather than restarting from scratch
Architecture
The overall framework of Graph-GRPO, illustrating the rollout collection, analytical rate estimation, and RL update loop.
Evaluation Highlights
- Achieves 97.5% Valid-Unique-Novelty (V.U.N.) on the Tree dataset, boosting the base model's performance from 73.5%
- Attains a 60% hit ratio on the parp1 protein docking task, which is 6x higher than the best baseline GDPO
- Sets a new state-of-the-art on the PMO benchmark with an AUC-top10 of 19.270 using prescreening and refinement
Breakthrough Assessment
9/10
Successfully makes discrete flow matching differentiable for RL, addressing a fundamental theoretical bottleneck. The empirical gains on molecular docking (6x hit ratio) and PMO benchmarks are substantial and practically valuable.