📝 Paper Summary
Reinforcement Learning with Verifiable Rewards
Mathematical Reasoning
Prompt augmentation trains models using diverse reasoning templates and format-specific rewards within a single run, preventing entropy collapse and enabling stable, long-horizon reinforcement learning for mathematical reasoning.
Core Problem
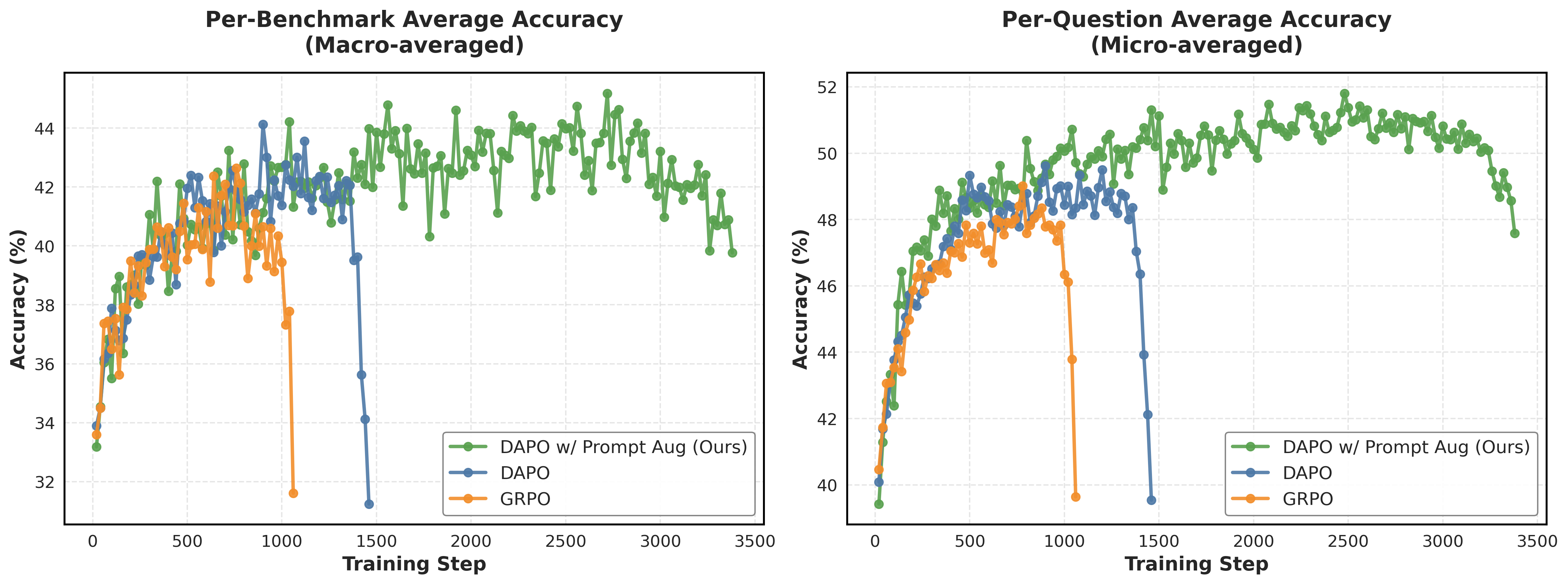
RL post-training for reasoning typically suffers from entropy collapse (monotonic decrease in policy entropy), leading to training instability and forcing short training horizons (5-20 epochs).
Why it matters:
- Entropy collapse restricts exploration of diverse reasoning paths, causing performance to saturate or degrade quickly
- Current methods rely on single fixed prompts, overfitting to one reasoning style and limiting the model's ability to generalize
- Short training horizons prevent models from fully exploiting the available compute and data for sustained improvement
Concrete Example:
When trained with a single standard template, a model's policy entropy drops near zero after ~10 epochs, causing it to output deterministic, repetitive responses. The proposed method maintains higher entropy, allowing training to continue productively for 50 epochs.
Key Novelty
Prompt Augmentation for RL Post-Training
- Mixes 13 different reasoning templates (e.g., DeepSeek-style tags, free-form, explicit Chain-of-Thought, reflection) within a single training run to force diverse rollout generation
- Applies template-specific format rewards to ensure the model adheres to the requested structure (e.g., rewarding usage of <think> tags only when the prompt demands it)
- Acts as a lightweight data augmentation strategy that stabilizes training dynamics without needing expensive KL divergence penalties
Architecture
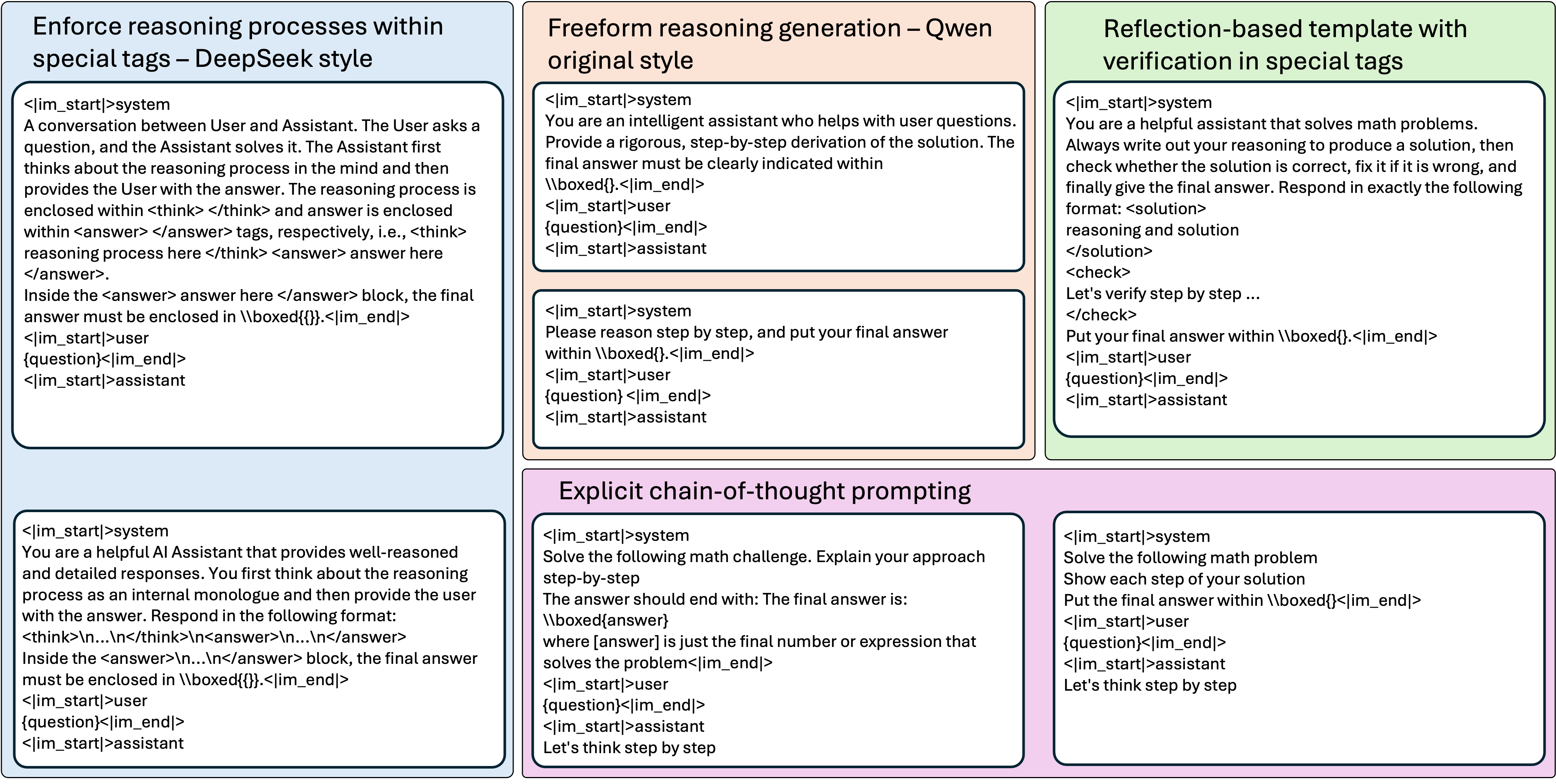
Overview of the template categories used for Prompt Augmentation.
Evaluation Highlights
- Achieves 51.8% per-question accuracy (average across 5 benchmarks) using Qwen2.5-Math-1.5B, outperforming DAPO (48.4%) and GRPO (47.7%)
- Enables stable training for 50 epochs, whereas baselines typically collapse or stop improving after 5-20 epochs
- +4.0% absolute improvement on AIME24 compared to the DAPO baseline (46.0% vs 42.0%)
Breakthrough Assessment
8/10
Simple yet highly effective solution to the pervasive entropy collapse problem in RLVR. By enabling significantly longer training horizons without complex regularization, it unlocks greater performance from existing models.