📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
LLM Reasoning
Post-training / Alignment
GRPO's standard advantage estimation treats correct and incorrect responses symmetrically, hindering exploration of new solutions and failing to adapt to changing problem difficulties during training.
Core Problem
GRPO suffers from two limitations: (1) capability boundary shrinkage, where it exploits known solutions rather than finding new ones, and (2) inadequate focus on problem difficulty, treating all tasks uniformly.
Why it matters:
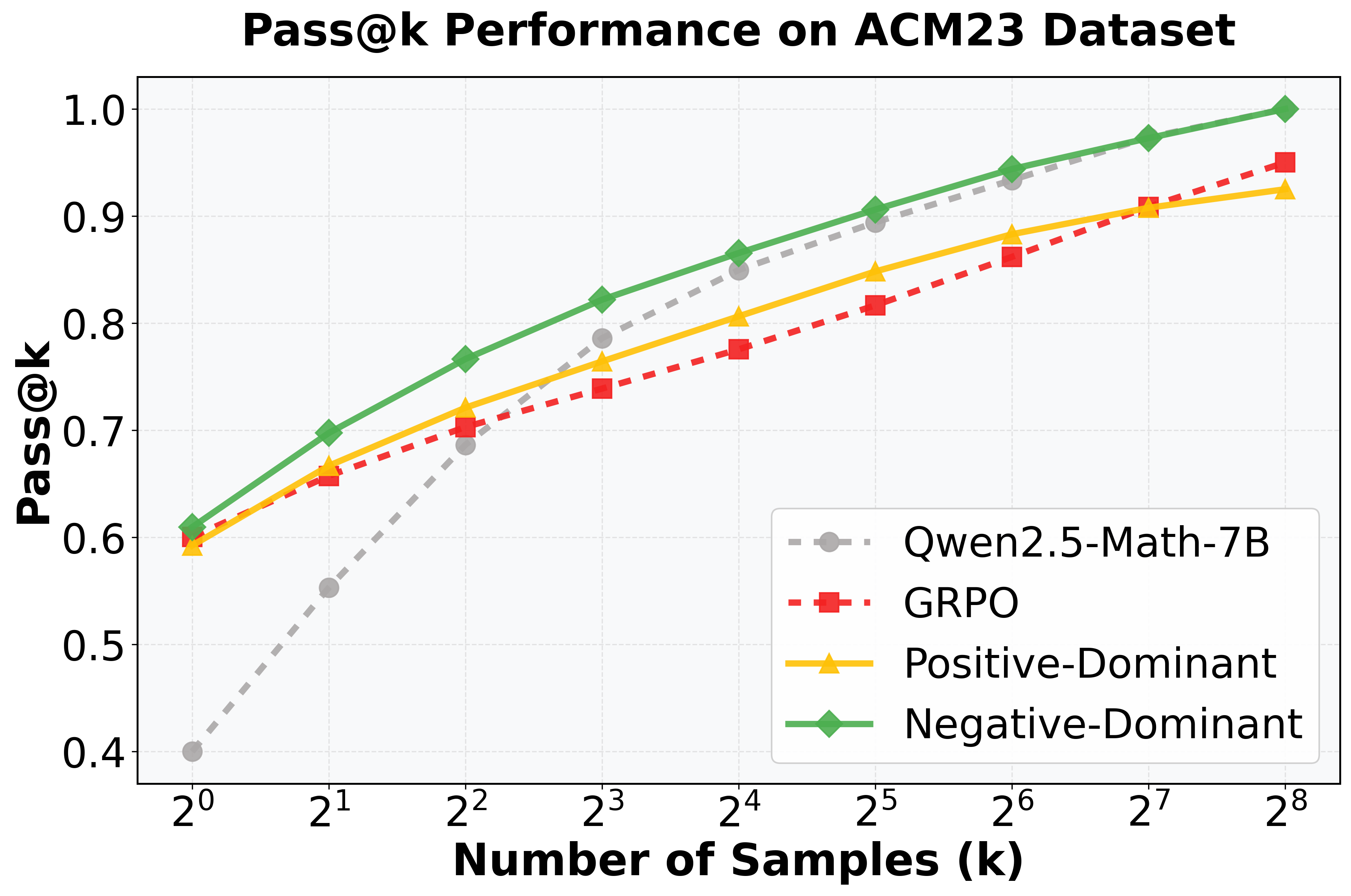
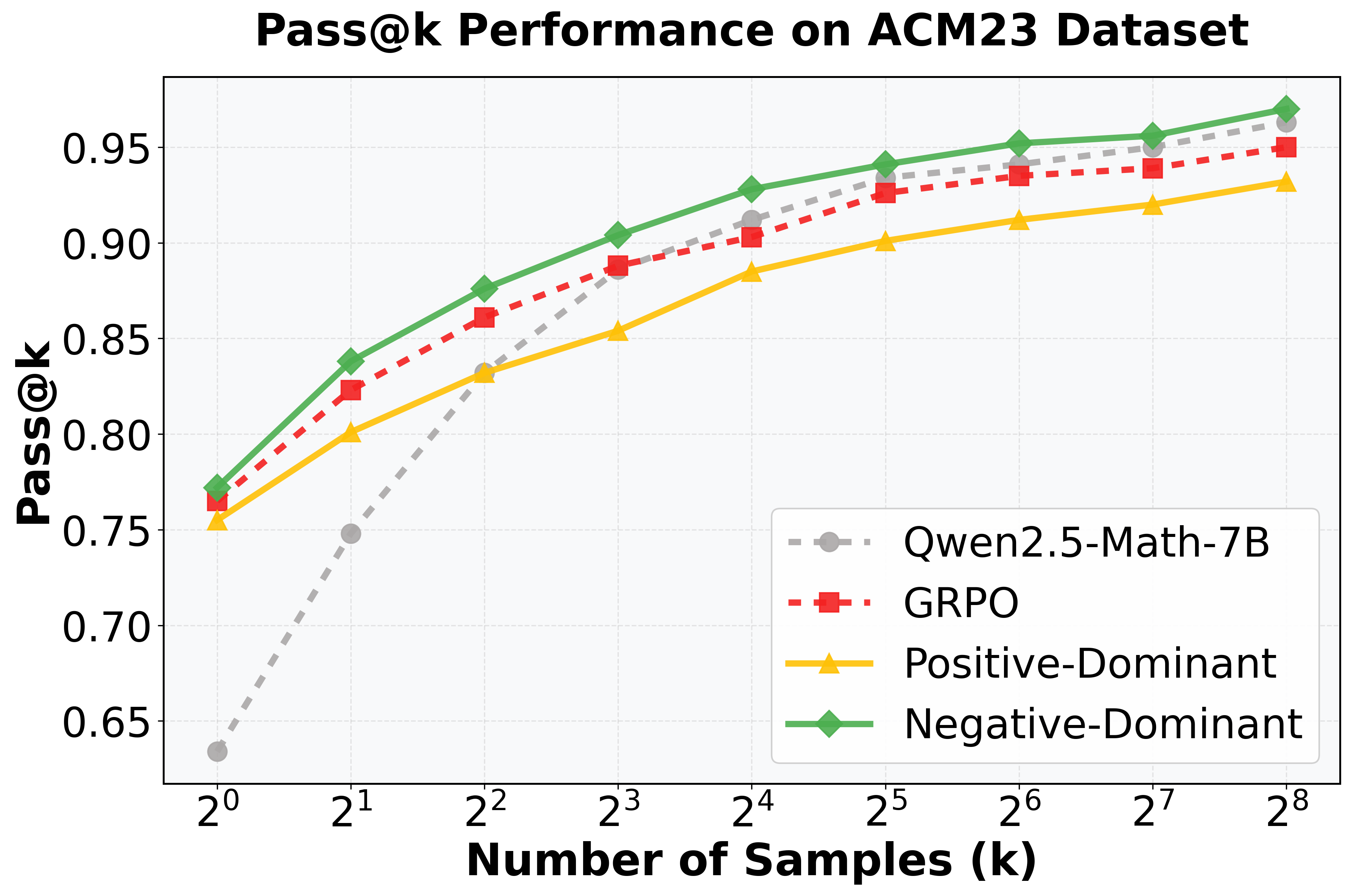
- Current reasoning models like DeepSeek-R1 rely on GRPO, but its Pass@k performance often drops below base models at large k, indicating failed exploration.
- Static difficulty weighting causes models to overfit simple tasks early on or fail to learn complex ones effectively as capabilities evolve.
- The standard zero-sum advantage formulation mathematically guarantees zero gradients for unsampled correct trajectories, locking the policy into local optima.
Concrete Example:
In mathematical reasoning (e.g., MATH dataset), standard GRPO improves Pass@1 but degrades Pass@256 below the base model, showing it narrows the solution search space rather than expanding it.
Key Novelty
Asymmetric Group Relative Advantage Estimation (A-GRAE)
- Breaks group-level symmetry by asymmetrically suppressing the advantage weights of correct trajectories relative to incorrect ones, forcing the model to explore new paths rather than just exploiting known correct ones.
- Breaks sample-level symmetry using a curriculum schedule that reweights updates based on sample success rate: prioritizing simple samples early for stability and hard samples later for capability expansion.
Architecture

Conceptual illustration of 'Implicit Advantage Symmetry' in GRPO. It visualizes how standard GRAE assigns equal magnitude weights to correct and incorrect trajectories and implicitly prioritizes medium-difficulty samples.
Evaluation Highlights
- Consistent improvements over GRPO, DAPO, and Dr.GRPO across 7 benchmarks (math and vision-language tasks).
- On AIME 2025 (Pass@1), A-GRAE with Qwen2.5-Math-7B achieves 22.3% compared to GRPO's 16.5% (+5.8%).
- On MATH (Pass@1), A-GRAE achieves 69.4% vs GRPO's 67.2% (+2.2%).
Breakthrough Assessment
8/10
Identifies a fundamental theoretical flaw in a widely used algorithm (GRPO) and proposes a simple, effective fix. The insight about 'advantage symmetry' is mathematically grounded and empirically validated.