📊 Experiments & Results
Evaluation Setup
Offline selection of 10% data subset followed by GRPO fine-tuning
Benchmarks:
- GSM8K (Grade school math reasoning)
- Tracking Shuffled Objects (BBH) (State tracking / Logic)
- AIME2025-I (OOD Advanced Math Competition)
Metrics:
- Accuracy (Exact Match)
- Learnable Percentage (fraction of steps with non-zero reward variance)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Main results comparing different difficulty selection strategies (Hard, Easy, Medium, Random) on GSM8K accuracy gains. | ||||
| GSM8K | Accuracy Gain (pp) | 0.0 | 39.42 | +39.42 |
| GSM8K | Accuracy Gain (pp) | 0.0 | 8.26 | +8.26 |
| GSM8K | Accuracy Gain (pp) | 0.0 | 37.3 | +37.3 |
| Out-of-distribution generalization results on the harder AIME2025 benchmark. | ||||
| AIME2025-I | Relative Improvement | 0.0 | 20.0 | +20.0 |
| Analysis of 'Base Wrong' vs 'Base Right' training splits. | ||||
| GSM8K | Relative Improvement | 0.0 | 23.5 | +23.5 |
Experiment Figures
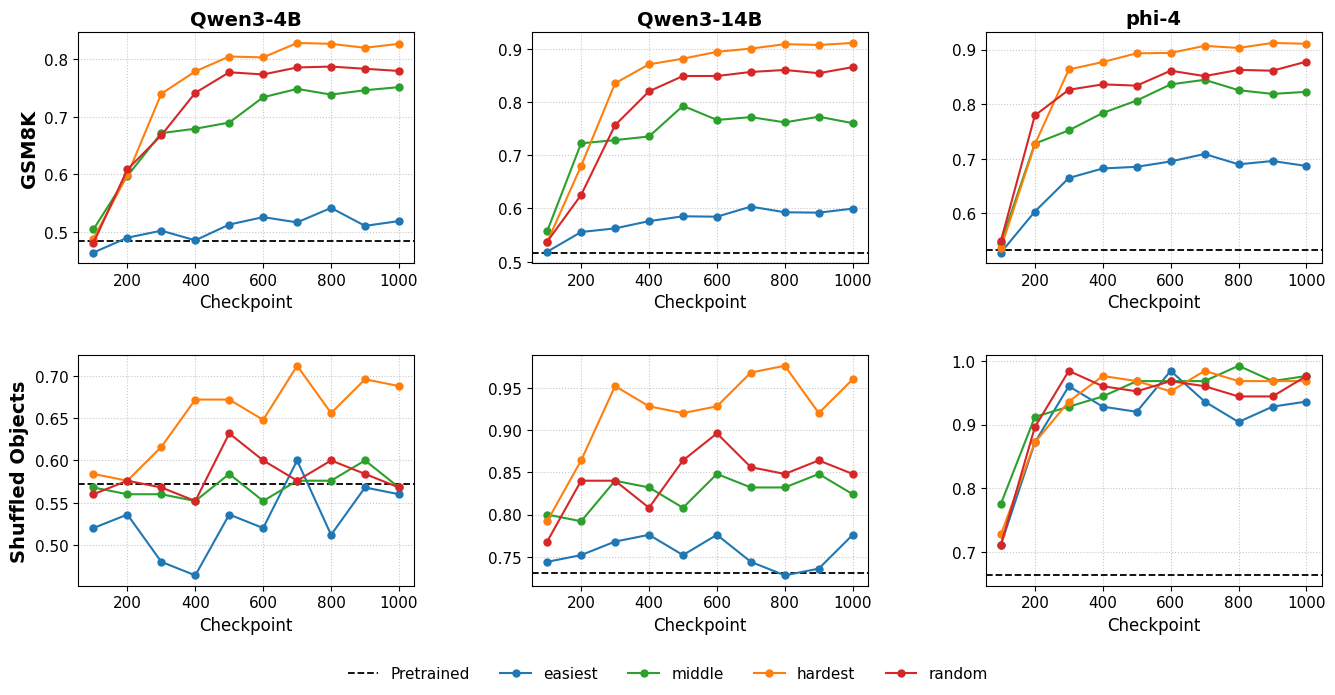
Learning curves (accuracy vs training steps) for different selection strategies.
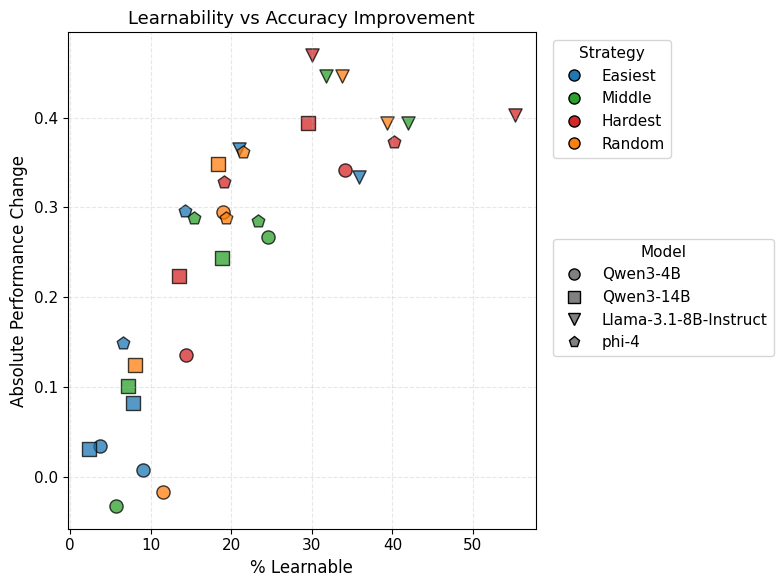
Correlation plot between '% Learnable' (x-axis) and Performance Improvement (y-axis).
Main Takeaways
- Hard Examples >> Easy Examples: There is a massive gap (>30pp) in effectiveness between training on hard vs. easy examples for GRPO.
- Mechanism is Reward Variance: Hard examples maintain 'learnability' (non-zero reward variance) for much longer; easy examples are solved quickly, causing gradients to vanish.
- Base-Wrong Heuristic: Simply selecting examples the base model gets wrong is a highly effective proxy for 'Hard' examples, avoiding complex pass@k estimation.
- OOD Generalization: Only models trained on hard examples showed robust transfer to the much harder AIME2025 benchmark; others stagnated or regressed.