📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Mathematical Reasoning
Data Augmentation
TA-GRPO improves reasoning models by training on diverse question phrasings and pooling rewards across them, preventing zero-gradient updates on easy/hard questions and reducing diversity collapse.
Core Problem
Standard GRPO suffers from gradient diminishing (zero gradients when all rollouts are correct/incorrect) and diversity collapse (reinforcing a single solution pattern), wasting over 80% of training questions.
Why it matters:
- LLMs trained on next-token prediction become pattern-matchers sensitive to superficial phrasing rather than robust reasoners
- Diversity collapse leads to suboptimal Pass@k performance because the model repeats the same strategy instead of exploring alternatives
- Gradient diminishing means questions that are too easy or too hard contribute no learning signal, inefficiently using compute and data
Concrete Example:
If a model always solves 'What is 2+3?' correctly (all rollouts reward=1), GRPO computes zero advantage and no update occurs. However, a paraphrased variant 'Calculate the sum of 2 and 3' might trigger different errors, providing a learning signal that standard GRPO ignores.
Key Novelty
Transform-Augmented GRPO (TA-GRPO)
- Augment each training question with semantically equivalent variants (paraphrasing, variable renaming, format changes) to expose the model to diverse solution patterns
- Pool advantage computation across the entire group of original + transformed questions rather than normalizing per-question
- Ensures mixed rewards (and thus non-zero gradients) even if the original question is too easy/hard, as variants will likely differ in difficulty
Architecture
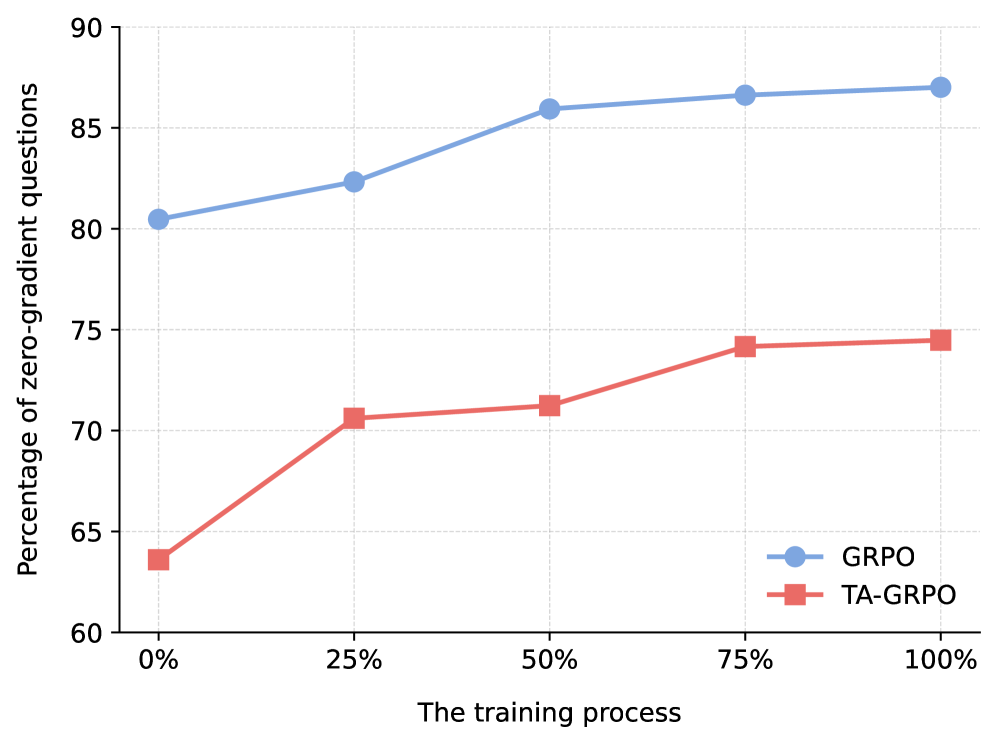
Comparison of 'zero-gradient' question frequency between GRPO and TA-GRPO over training steps.
Evaluation Highlights
- +9.84 Pass@32 improvement on competition math benchmarks (AMC12 + AIME24) using Qwen2.5-Math-7B
- +5.05 Pass@32 improvement on out-of-distribution scientific reasoning (GPQA-Diamond), showing better generalization
- Reduces the percentage of zero-gradient questions by 12–16 points throughout training compared to standard GRPO
Breakthrough Assessment
8/10
Simple yet theoretically grounded fix for a major inefficiency in GRPO (80% wasted data). Significant empirical gains on hard benchmarks suggest this could become a standard practice for RLVR.