📝 Paper Summary
Reinforcement Learning for LLMs
Mathematical Reasoning
Feedback Mechanisms
Critique-GRPO augments standard numerical RL by incorporating natural language critiques into the training loop, enabling models to learn from both initial trial-and-error attempts and critique-guided refinements.
Core Problem
Purely numerical RL (scalar rewards) suffers from performance plateaus, ineffective spontaneous self-reflection, and persistent failures where models cannot correct errors despite extensive training.
Why it matters:
- Numerical rewards lack expressivity to explain why a response failed or how to fix it, leading to inefficient exploration
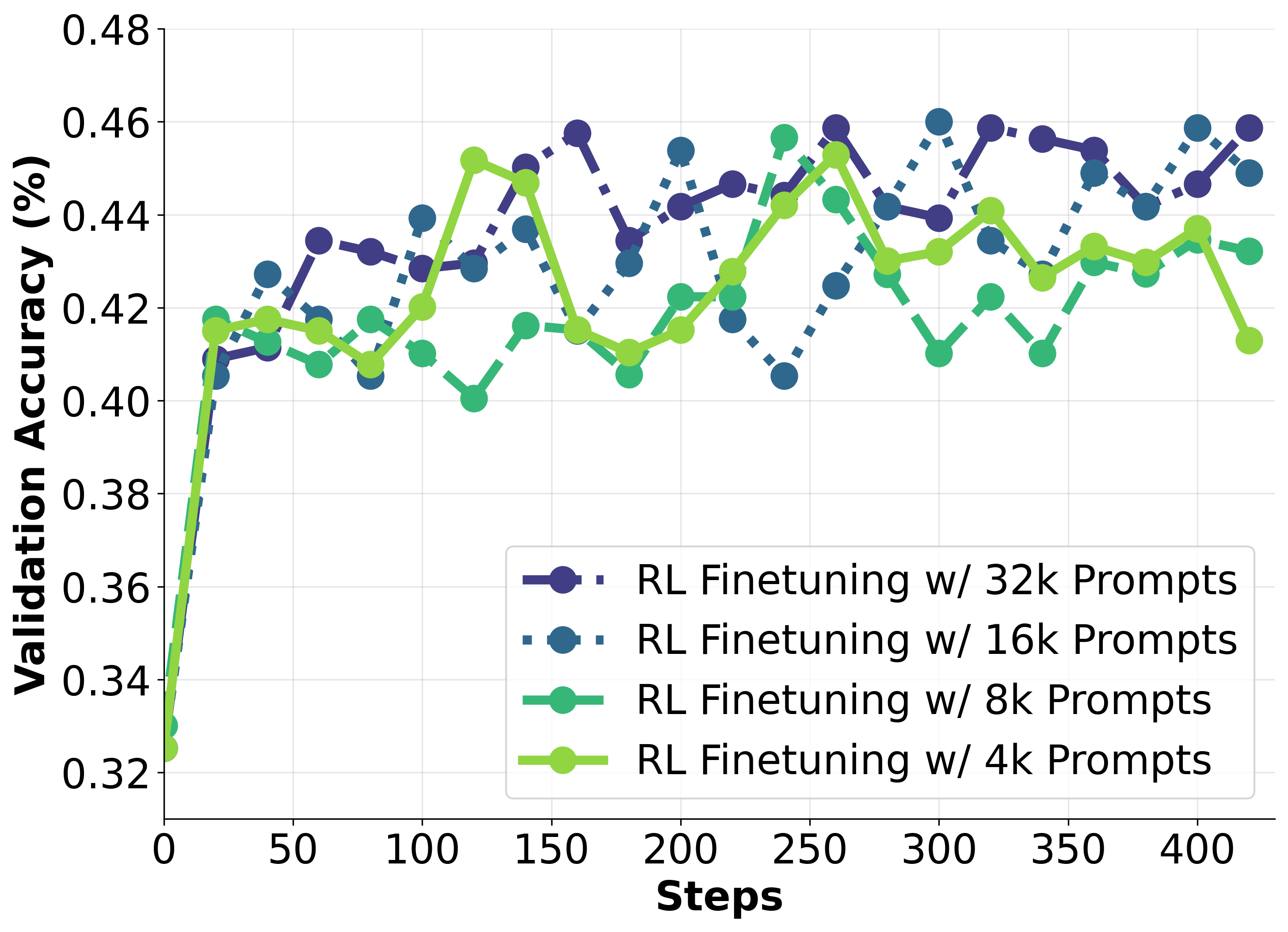
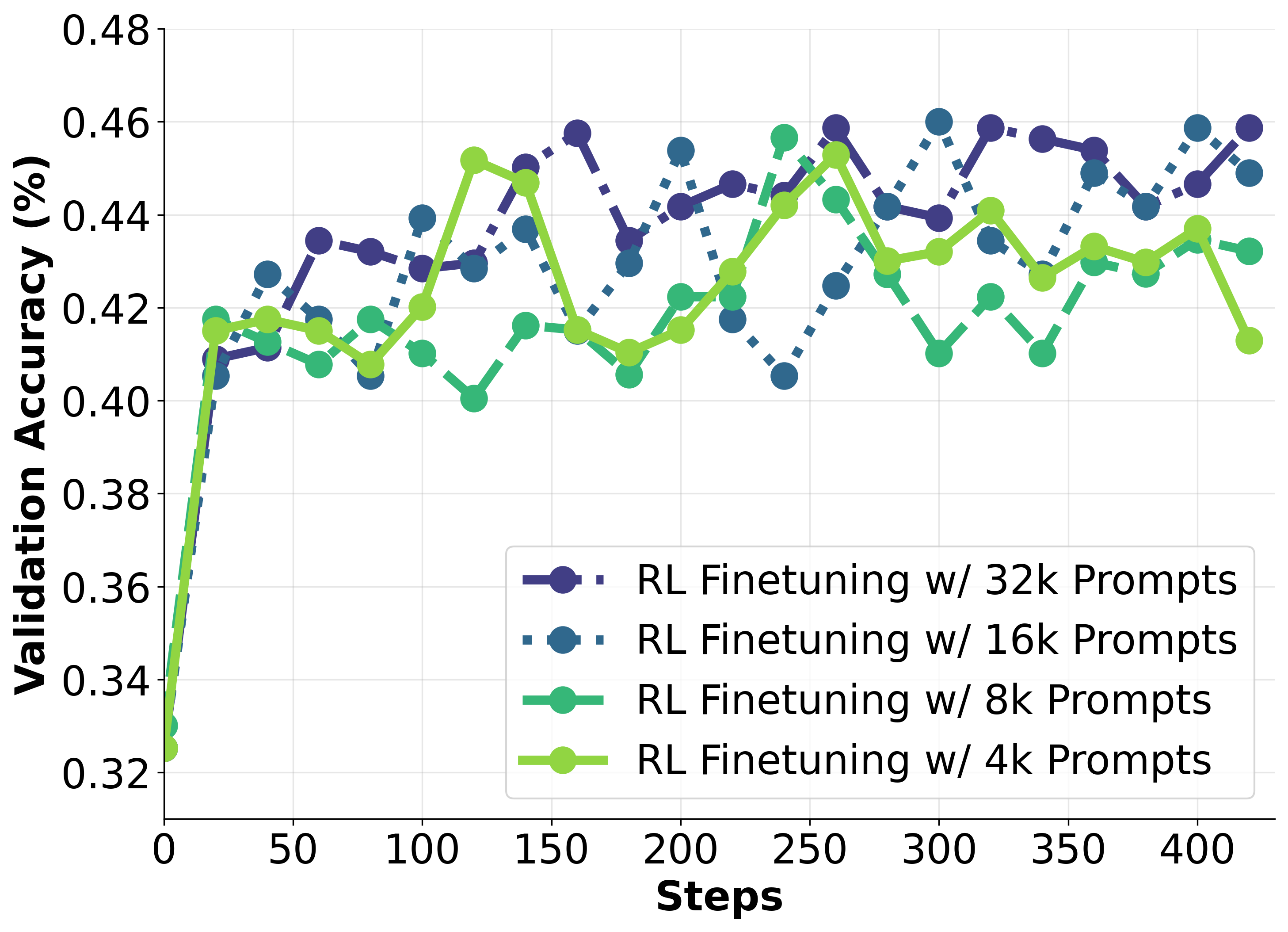
- Current methods like R1-Zero plateau even with 8x data scaling
- Existing critique methods rely on static SFT (offline), lacking the active exploration benefits of online RL
Concrete Example:
A Qwen2.5-7B-Base model trained with numerical RL consistently fails on ~29% of training questions (Pass@4=0) and performance saturates after 120 steps. Spontaneous 'aha moments' (self-correction) rarely occur or improve success rates in these cases.
Key Novelty
Critique-GRPO (Group Relative Policy Optimization with Critiques)
- Dual learning mechanism: The model generates initial responses via standard exploration AND refined responses via in-context learning guided by generated critiques
- Integrates critiques directly into the online RL loop (GRPO) rather than just supervised fine-tuning, allowing the policy to update based on both trial-and-error and explicit verbal guidance
- Uses a shaping function to reinforce valid but unfamiliar refinement trajectories, penalizing incorrect attempts while encouraging the model to adopt successful reasoning patterns found via critique
Architecture
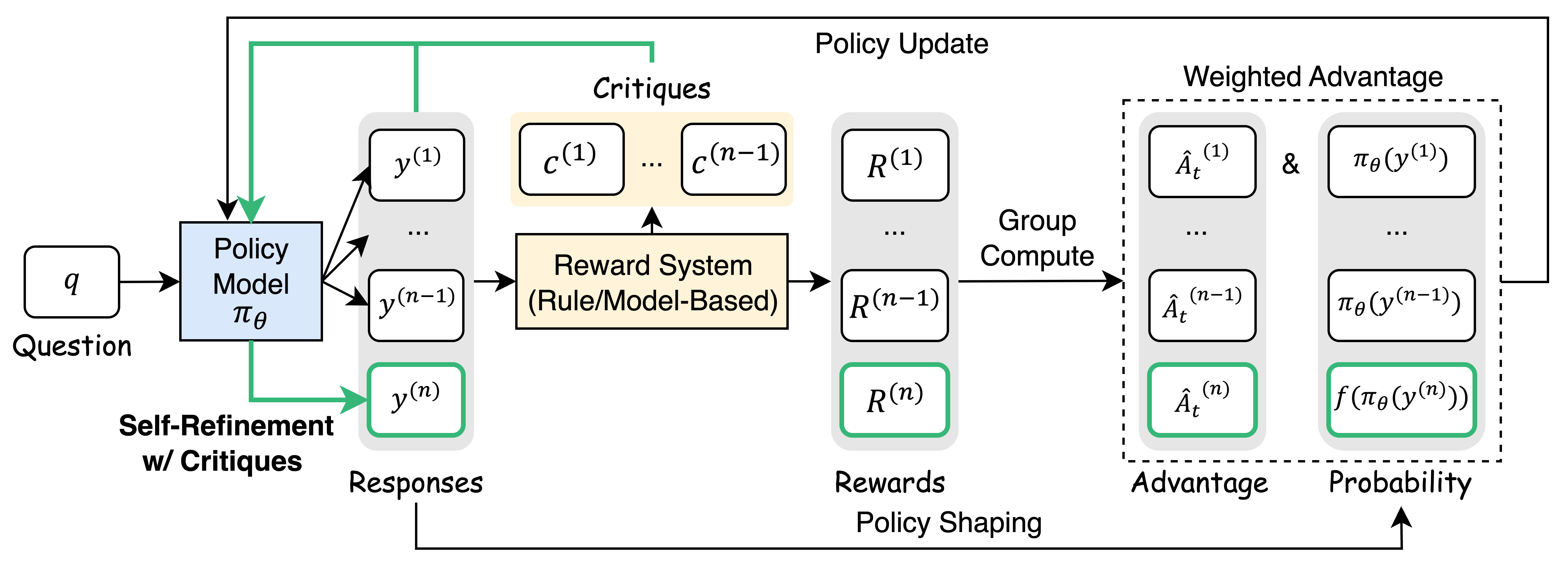
The Critique-GRPO workflow. It illustrates the parallel process of standard generation and critique-guided refinement within the RL loop.
Evaluation Highlights
- +15.0-21.6% average Pass@1 improvement on Qwen models (Base and Instruct) across 8 reasoning tasks compared to baselines
- +16.7% Pass@1 gain over standard GRPO on the AIME 2024 benchmark when using self-critiques
- +7.3% average Pass@1 improvement on Llama-3.2-3B-Instruct across 8 tasks
Breakthrough Assessment
8/10
Strong empirical results solving the 'plateau' problem of numerical RL. Successfully integrates verbal feedback into online RL without needing expert demonstrations, a significant step for self-improving models.