📝 Paper Summary
Visual Large Language Models (VLLMs)
Reinforcement Learning for Vision (RLVR)
Visual Segmentation and Detection
Dr. Seg adapts Group Relative Policy Optimization for visual perception by forcing the model to explicitly explore visual cues and normalizing continuous rewards via dynamic quantile ranking.
Core Problem
Training paradigms like GRPO, originally designed for reasoning tasks (math/logic), fail to transfer optimally to visual perception because they encourage depth-first convergence rather than breadth-first exploration of visual cues.
Why it matters:
- Directly applying reasoning-oriented RL (binary rewards, causal chain focus) to vision leads to suboptimality and unstable training
- Perception tasks require balancing multiple heterogeneous metrics (IoU, counts, point distance) with different scales, which causes high-variance objectives to dominate gradients in standard GRPO
- Current methods relying solely on instruction tuning suffer from limited generalization and catastrophic forgetting
Concrete Example:
In a reasoning segmentation task, a standard GRPO model might quickly converge to a narrow reasoning path and output a loose bounding box. Because the reward is binary or unnormalized, the model receives noisy feedback. In contrast, Dr. Seg forces the model to generate a <look> tag to verify visual details (e.g., shape, color) and uses a ranked IoU score to provide fine-grained gradient signals for tighter boxes.
Key Novelty
Perception-Oriented GRPO Framework (Dr. Seg)
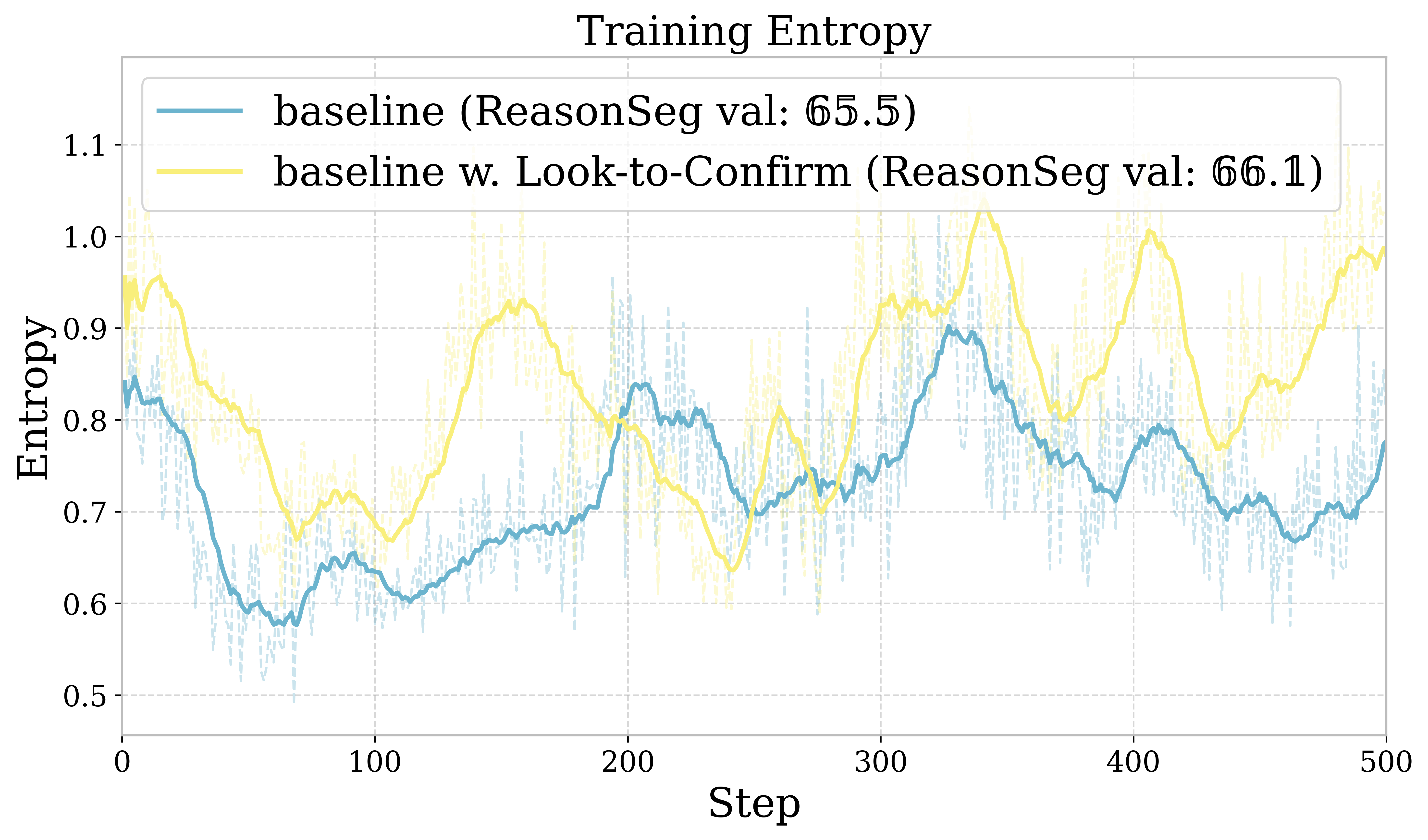
- **Look-to-Confirm Strategy**: Explicitly prompts the model to generate `<look>` tags, forcing it to broaden its search space and attend to diverse visual evidence (shape, material, relations) before concluding.
- **Distribution-Ranked Reward**: Replaces raw metric values with their empirical quantile (rank) within a rolling history queue, creating a scale-invariant reward that prevents high-variance metrics from dominating optimization.
Architecture

The Look-to-Confirm mechanism where the model generates <look> tags to attend to visual regions.
Evaluation Highlights
- +2.0 absolute gIoU improvement on the ReasonSeg-test segmentation benchmark compared to the baseline method.
- +2.4 absolute AP on the COCO detection benchmark.
- +4.5 improvement on the Pixmo-val counting benchmark.
Breakthrough Assessment
8/10
Identifies a fundamental mismatch between reasoning-based RL and perception tasks. The proposed rank-based reward normalization is a generalizable solution for multi-objective RL in vision.