📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Post-training / Alignment
XRPO improves reinforcement learning for reasoning by dynamically allocating rollouts to high-uncertainty prompts and sharpening rewards for novel correct solutions, balancing exploration and exploitation.
Core Problem
Standard GRPO uses static rollout allocation (e.g., 16 per prompt) and sparse binary rewards, causing under-exploration of high-variance prompts and under-exploitation of informative trajectories.
Why it matters:
- Static allocation wastes compute on easy/solved prompts while failing to gather sufficient signal for uncertain edge-cases
- Hard prompts with zero rewards provide no gradient signal, causing stagnation on difficult reasoning tasks
- Binary rewards treat all correct answers equally, ignoring that rare/novel correct solutions often contain richer learning signals than rote memorization
Concrete Example:
For a hard math problem where a model currently scores 0%, standard GRPO generates 16 failing rollouts, yielding zero gradients. XRPO detects this failure, seeds the prompt with in-context examples to find a correct path, and then prioritizes it for further exploration.
Key Novelty
Explore-Exploit GRPO (XRPO)
- Hierarchical Rollout Planner: Dynamically allocates the rollout budget in phases, prioritizing prompts where additional sampling is expected to most reduce statistical uncertainty about the reward mean.
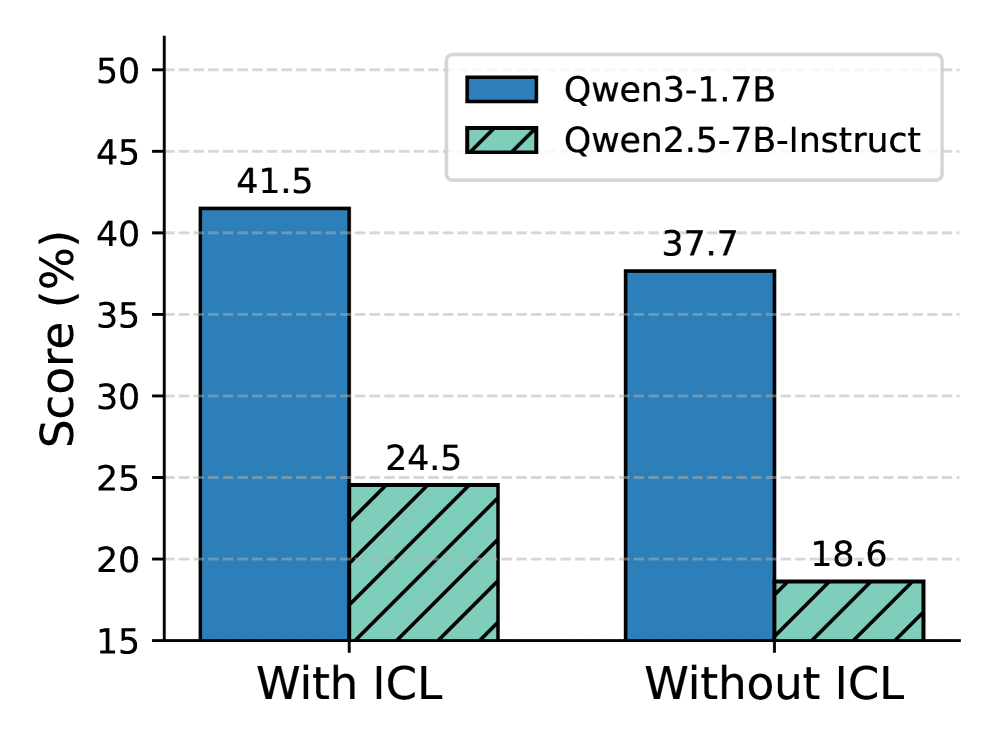
- In-Context Learning (ICL) Seeding: Detects 'degenerate' groups (all-fail) and injects solved examples from similar tasks into the context to break the zero-reward symmetry and jump-start learning.
- Novelty-Guided Advantage Sharpening: Boosts the reward signal for correct answers that have lower sequence likelihoods (higher novelty), encouraging the model to learn atypical but valid reasoning paths.
Architecture
The XRPO training loop: Phased rollout allocation → ICL Seeding → Rollout Generation → Novelty-Guided Advantage Update.
Evaluation Highlights
- Outperforms vanilla GRPO and recent methods (GSPO) by up to 4% pass@1 and 6% cons@32 on math/coding benchmarks.
- Accelerates training convergence by up to 2.7x compared to standard GRPO baselines.
- Achieves higher task success rates under the same rollout budgets, doubling sample efficiency.
Breakthrough Assessment
8/10
Strong methodological contribution addressing the core efficiency bottleneck of RLVR (rollout allocation). The combination of active exploration with ICL seeding for hard prompts is a practical and effective innovation.