📝 Paper Summary
Reinforcement Learning for LLMs
Mathematical Reasoning
Reward Engineering
GTPO and GRPO-S improve LLM reasoning by using policy entropy to dynamically redistribute rewards, assigning higher credit to uncertain steps in correct solutions and penalizing confident errors.
Core Problem
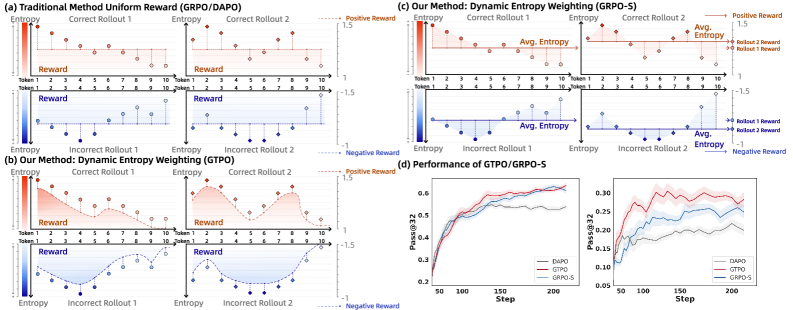
Mainstream RL algorithms like GRPO use coarse-grained credit assignment, giving identical rewards to all tokens in a sequence based solely on the final outcome.
Why it matters:
- Long reasoning chains with a single final error receive zero reward, penalizing the many correct intermediate logical steps.
- Conversely, sequences reaching the correct answer through flawed or guessed steps receive full reward, reinforcing bad reasoning.
- Existing methods treat entropy only as a regularizer or filter, failing to actively reshape the reward signal for better supervision.
Concrete Example:
A math reasoning sequence with dozens of correct logical steps might end with a calculation error, resulting in a binary reward of 0. GRPO treats this entire sequence as equally 'bad' as a completely nonsensical answer, wasting valuable training signal from the correct intermediate steps.
Key Novelty
Dynamic Entropy Weighting
- Repurposes policy entropy as a proxy for 'cognitive effort' or 'pivotal decision points' rather than just noise.
- In correct solutions, high entropy signals valuable exploration (difficult steps navigated correctly) and receives a reward bonus.
- In incorrect solutions, low entropy signals 'confident errors' and receives a heavier penalty to discourage stubborn incorrect reasoning.
Architecture
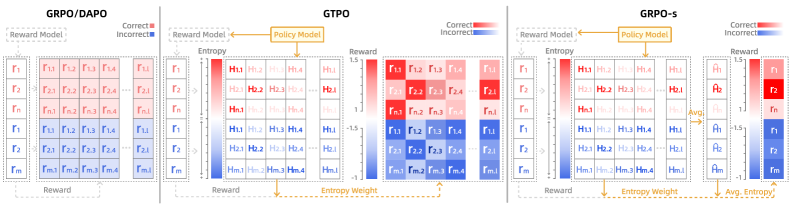
Illustration of the Dynamic Entropy Weighting mechanism. It contrasts 'Coarse-grained Reward' (GRPO) with the proposed method.
Evaluation Highlights
- GTPO achieves +6.8% accuracy improvement on MATH 500 compared to GRPO using Qwen2.5-Math-7B.
- GRPO-S outperforms GRPO by +3.5% on the AIME 2024 benchmark using Llama-3.1-8B-Instruct.
- GTPO outperforms the strong baseline DAPO by +2.2% on MATH 500 using Qwen2.5-Math-7B.
Breakthrough Assessment
8/10
Offers a theoretically grounded and empirically effective solution to the long-standing credit assignment problem in RLHF without requiring an external value model (critic).