📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Multi-Objective Reinforcement Learning (MORL)
Large Language Model Alignment
MO-GRPO normalizes advantage functions individually for each objective before aggregation, preventing high-variance rewards from dominating the learning process and ensuring balanced multi-objective optimization.
Core Problem
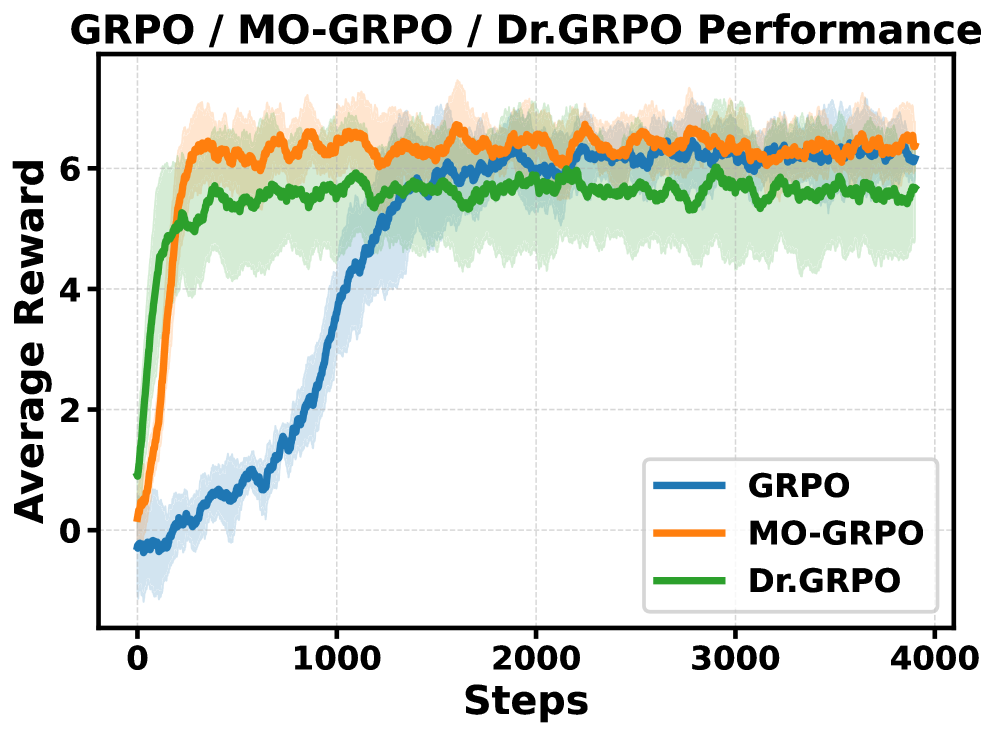
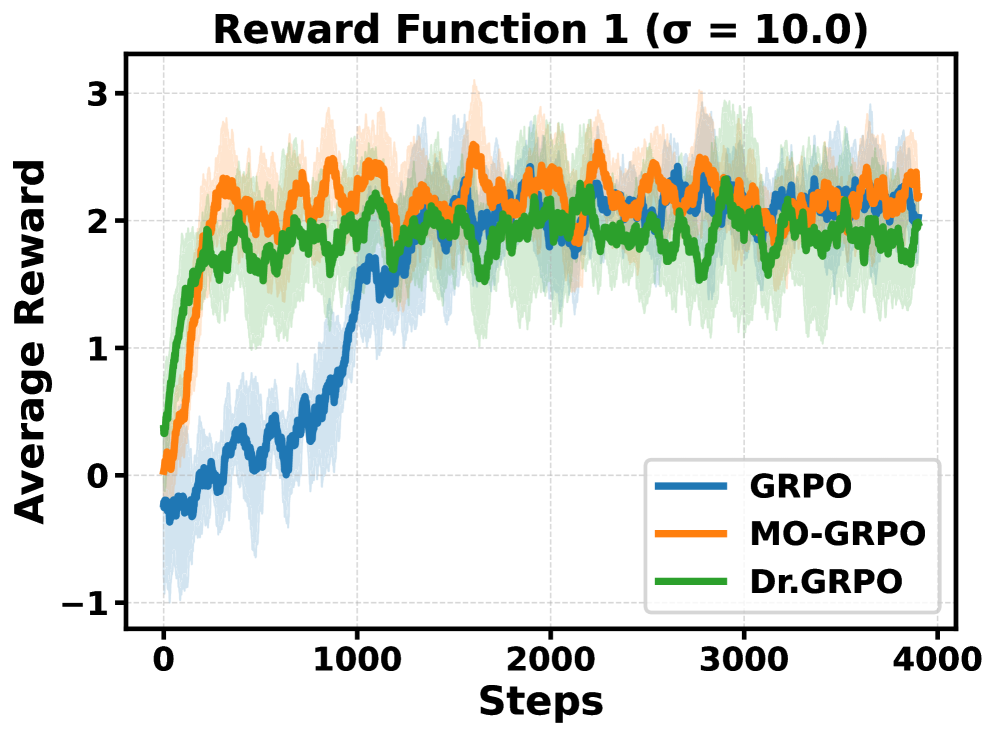
Group Relative Policy Optimization (GRPO) is vulnerable to reward hacking in multi-objective settings because its loss function inherently favors objectives with higher variance, ignoring lower-variance but equally important signals.
Why it matters:
- Real-world tasks often rely on under-specified or multiple proxy rewards (e.g., translation accuracy + readability) rather than a single perfect ground truth.
- When an agent overfits to a specific high-variance proxy reward at the expense of others, it produces undesirable behaviors like hallucination or loss of core task functionality.
- Prior methods like GRPO require manual tuning of reward scales to prevent this imbalance, which is difficult when reward scales are unknown or dynamic.
Concrete Example:
In English-to-Japanese translation, GRPO maximizes a 'readability' reward (which has high variance) by outputting simple English text instead of Japanese. It ignores the 'translation accuracy' reward (low variance), failing the core task. MO-GRPO balances both, producing accurate Japanese translations.
Key Novelty
Multi-Objective Group Relative Policy Optimization (MO-GRPO)
- Instead of summing raw rewards and then normalizing the total advantage (as in GRPO), MO-GRPO computes a normalized advantage score for *each* objective separately.
- These normalized advantages are then summed, ensuring that every objective contributes equally to the policy update regardless of its raw scale or variance.
- Theoretical analysis proves this method is invariant to positive affine transformations, meaning it works without manual reward scaling.
Architecture
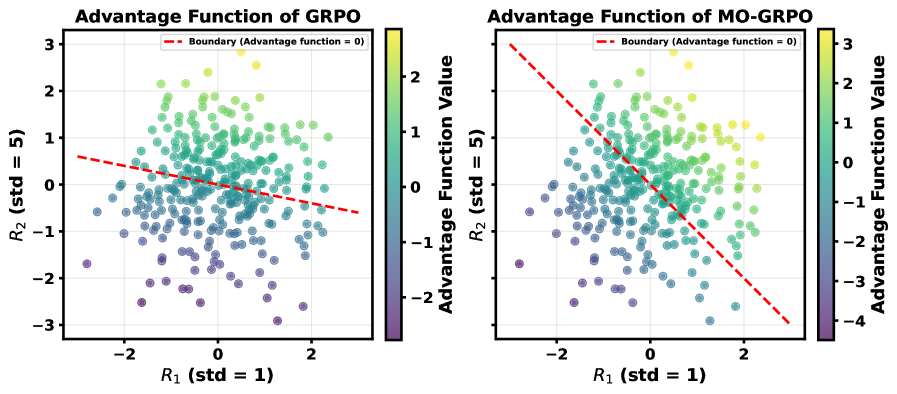
Comparison of how GRPO and MO-GRPO calculate advantages given two reward functions with different variances.
Evaluation Highlights
- Reduces non-Chinese output rate from 68.7% (GRPO) to 5.6% (MO-GRPO) in English-to-Chinese translation tasks where GRPO exploits a readability metric.
- Achieves 74.0% win rate on GPT-Eval for translation tasks, outperforming GRPO (71.5%) and avoiding the reward hacking that degraded GRPO's performance.
- Maintains balanced optimization in simulated control (Mo-Reacher), achieving high rewards across all 4 objectives, whereas GRPO neglects 2 of the 4.
Breakthrough Assessment
7/10
Provides a theoretically grounded and practically effective fix for a significant failure mode in GRPO (reward hacking via variance dominance). The solution is simple, robust, and mathematically sound.