📝 Paper Summary
Reinforcement Learning from Verifiable Rewards (RLVR)
Large Language Model Reasoning
CoRPO modifies Group-Relative Policy Optimization (GRPO) by clipping the baseline at a fixed correctness threshold, preventing incorrect solutions from receiving positive reinforcement simply because they outperform a poor group average.
Core Problem
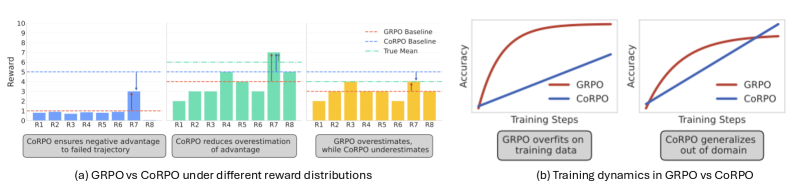
GRPO's group-mean baseline can assign positive advantages to objectively incorrect solutions if they outperform other failures in a sampled group, leading to the reinforcement of bad behaviors.
Why it matters:
- Reinforcing incorrect trajectories that happen to be 'less bad' than peers inverts the desired learning signal, effectively teaching the model to fail in specific ways.
- GRPO exhibits 'distribution sharpening,' where it prematurely exploits specific solution paths rather than exploring, degrading diversity and robustness.
- Standard relative baselines fail when rewards are ordinal (graded) rather than binary, as they measure rank rather than objective correctness.
Concrete Example:
In a coding task where a model generates 4 incorrect solutions with rewards -1, -0.8, -0.9, and -0.7, the group mean is -0.85. The solution with reward -0.7 is objectively wrong (failed test cases) but receives a positive advantage (+0.15), reinforcing a failed attempt.
Key Novelty
Correctness-Relative Policy Optimization (CoRPO)
- Modifies the advantage estimation by clipping the group-mean baseline at a minimum correctness threshold (e.g., the passing score).
- Creates a dual-regime baseline: acts as a static quality threshold when group performance is poor (correctness-seeking), and reverts to a relative group mean when performance is good (quality-seeking).
Architecture
Conceptual illustration of the CoRPO baseline clipping mechanism compared to GRPO
Evaluation Highlights
- CoRPO outperforms GRPO on out-of-domain (OOD) tasks, indicating better generalization of reasoning patterns.
- Analysis of training dynamics shows CoRPO mitigates 'distribution sharpening,' maintaining higher entropy/exploration compared to GRPO's rapid collapse.
- Demonstrates cross-domain transfer: CoRPO models trained on code improve on math tasks, whereas GRPO models often fail to transfer effectively.
Breakthrough Assessment
7/10
Identifies a subtle but critical flaw in the widely used GRPO baseline for reasoning tasks. The solution is mathematically simple, theoretically grounded, and addresses the specific issue of ordinal rewards in RLVR.