📝 Paper Summary
LLM Reasoning
Reinforcement Learning for LLMs
Post-training optimization
GRPO-λ improves LLM reasoning by incorporating eligibility traces into the critic-free GRPO algorithm, enabling better credit assignment to earlier tokens in generated sequences without a value network.
Core Problem
The state-of-the-art GRPO algorithm lacks a critic model, which prevents fine-grained credit assignment across tokens; it relies on group averages that become increasingly biased for later tokens in a sequence.
Why it matters:
- Effective reasoning requires identifying exactly which steps in a long chain of thought led to the correct solution
- Standard GRPO assigns the same sparse reward to all tokens, failing to distinguish crucial reasoning steps from irrelevant ones
- Training a separate critic model (like in PPO) is memory-intensive and difficult due to the disparity between the pre-trained policy and the initialized critic
Concrete Example:
In a multi-step math problem, if an LLM generates a correct answer, GRPO rewards every token equally. However, if the model made a lucky guess after a flawed intermediate step, GRPO reinforces the flaw. GRPO-λ uses traces to propagate the final reward back to earlier, critical decision points more effectively.
Key Novelty
Critic-free Eligibility Traces for LLMs (GRPO-λ)
- Reformulates Generalized Advantage Estimation (GAE) to work without a critic model by using token-level log-probabilities and group-relative rewards
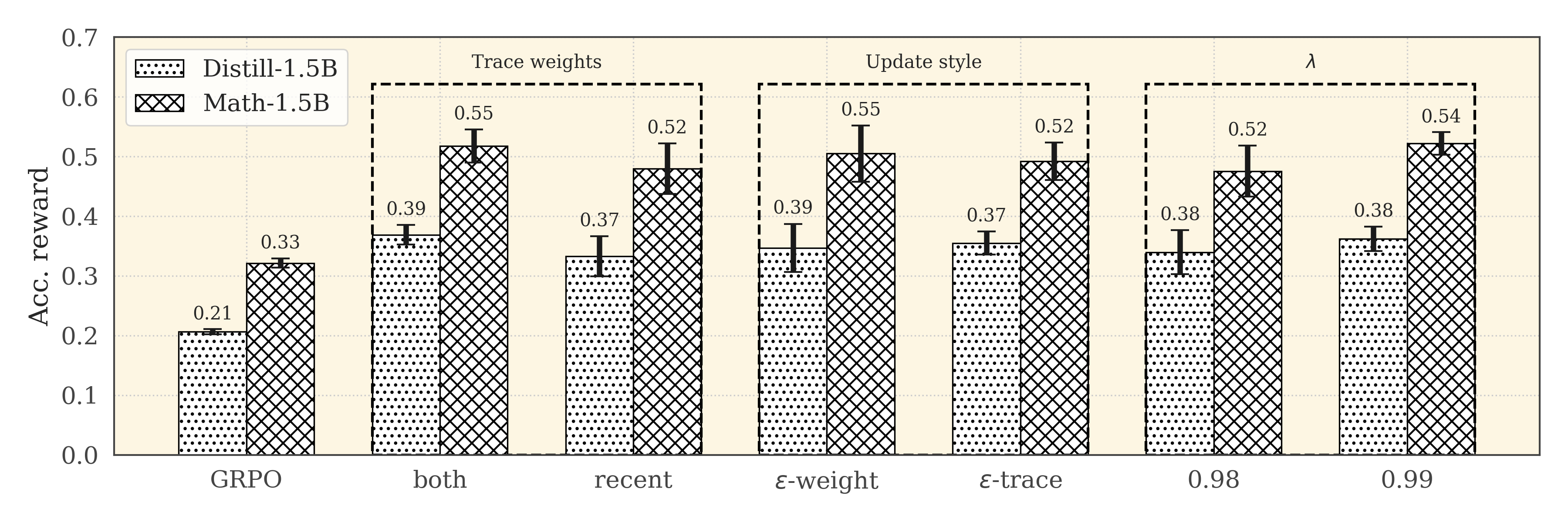
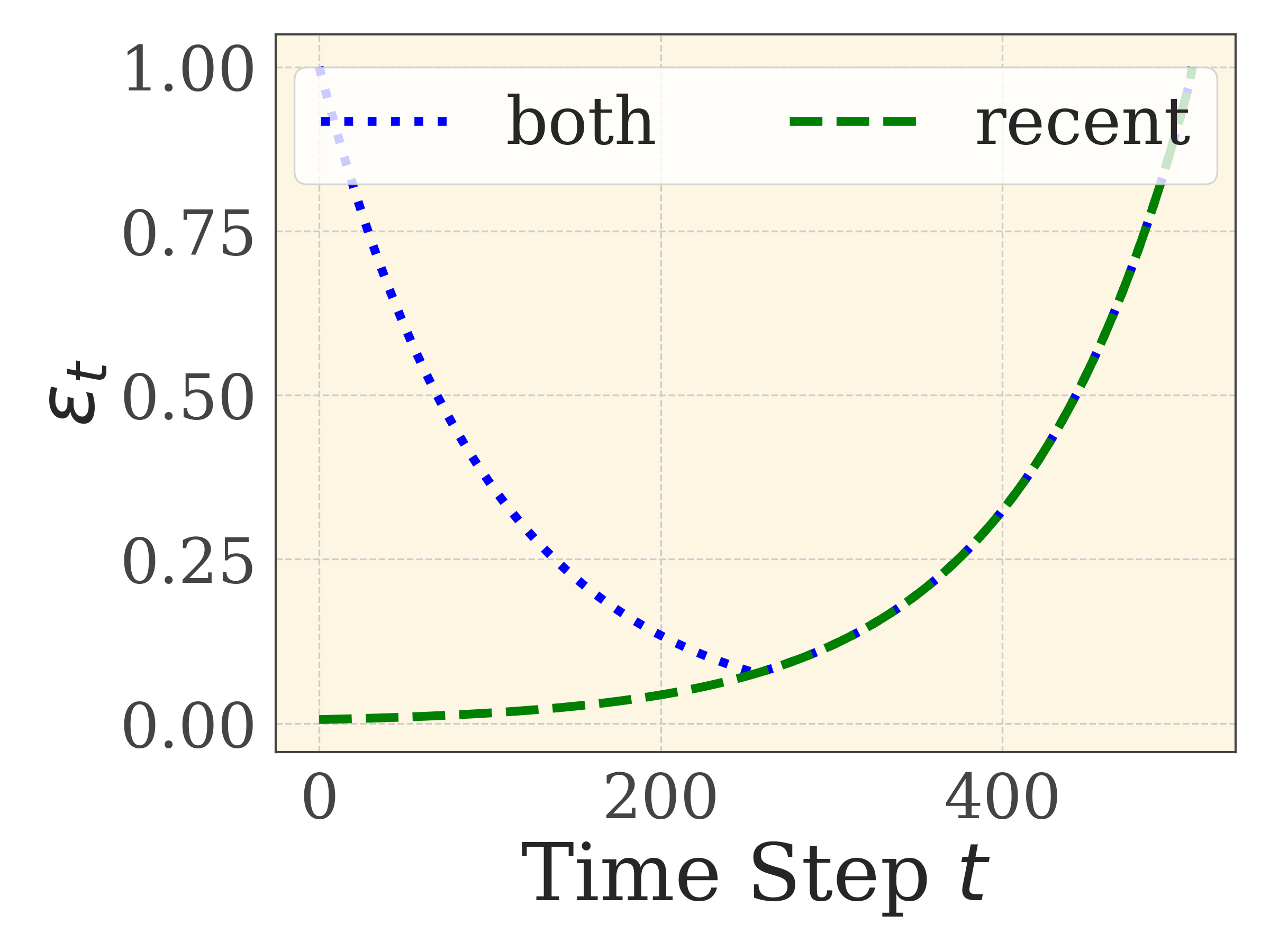
- Introduces a 'both' weighting strategy that balances credit assignment between early tokens (which have lower value estimation error) and late tokens (which are closer to the final reward)
- Proves a bound on the error of using start-state value estimates for later tokens, justifying the need for decaying weights on intermediate steps
Architecture
Pseudocode for GRPO-λ showing how eligibility traces are integrated into the GRPO update loop.
Evaluation Highlights
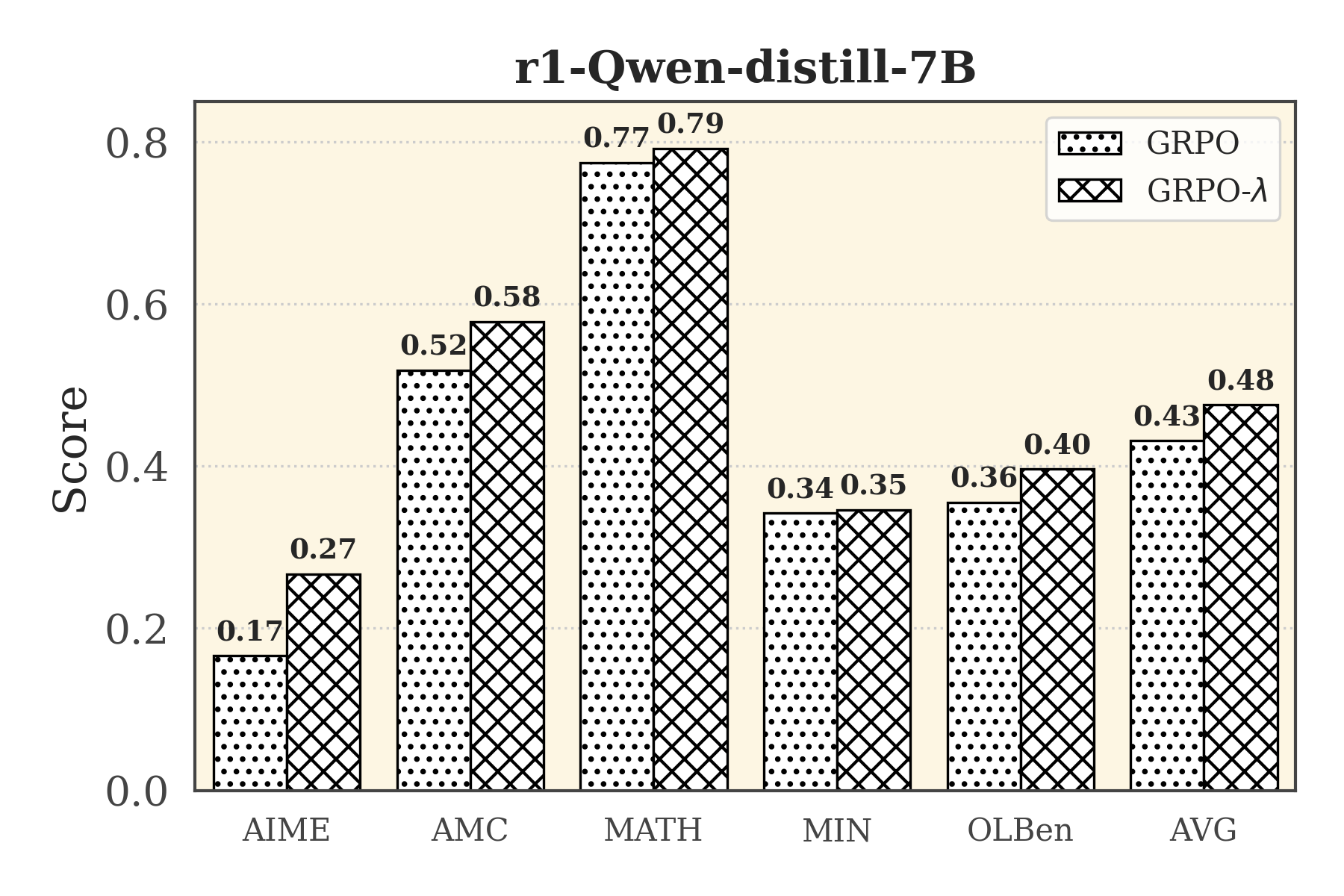
- +33 points average improvement over GRPO across 5 benchmarks (AIME24, Math500, OlympiadMath, MinervaMath, AMC)
- 30-40% improved performance during RL training on LLaMA-3.1 and Qwen-2.5 architectures compared to standard GRPO
- +4.5 points improvement on the Deepseek-R1-Distill-Qwen-7B model compared to GRPO baseline
Breakthrough Assessment
8/10
Offers a mathematically grounded, memory-efficient improvement to the current SFT/RL pipeline for reasoning. Significant empirical gains (+33 points) without the overhead of a critic model make it highly practical.