📝 Paper Summary
Representation Learning
Reinforcement Learning for Computer Vision
Visual Transformers (ViT) Fine-tuning
GRPO-RM adapts the Group Relative Policy Optimization method from LLMs to visual representation models by treating classification as a token selection task and introducing alignment-uniformity rewards.
Core Problem
Standard fine-tuning of representation models relies on supervised cross-entropy, missing the benefits of reinforcement learning alignment (like GRPO in LLMs) due to architectural differences between generative token sampling and deterministic visual feature extraction.
Why it matters:
- Representation models (e.g., DINOv2) require robust post-training to adapt to downstream tasks like classification and segmentation
- Current fine-tuning methods do not leverage the group-wise optimization advantages seen in recent LLM breakthroughs (DeepSeek-R1)
- Directly applying GRPO is impossible because vision models output deterministic embeddings, not probabilistic token sequences with reasoning traces
Concrete Example:
In standard fine-tuning, a model is updated based on a single prediction's error. In GRPO-RM, the model generates a 'group' of outputs (probability distribution over classes) for an image, and updates are driven by the relative advantage of correct vs. incorrect classes, using uniformity rewards to suppress wrong predictions dynamically.
Key Novelty
Group Relative Policy Optimization for Representation Models (GRPO-RM)
- Reframes visual classification as a 'response generation' task where the class set acts as the response space, enabling GRPO-style sampling
- Replaces token-level reasoning rewards with a novel 'Accuracy + Uniformity' reward function tailored for embedding space properties (alignment and uniformity)
- Eliminates the reference model (KL divergence) to simplify the objective for representation learning contexts
Architecture
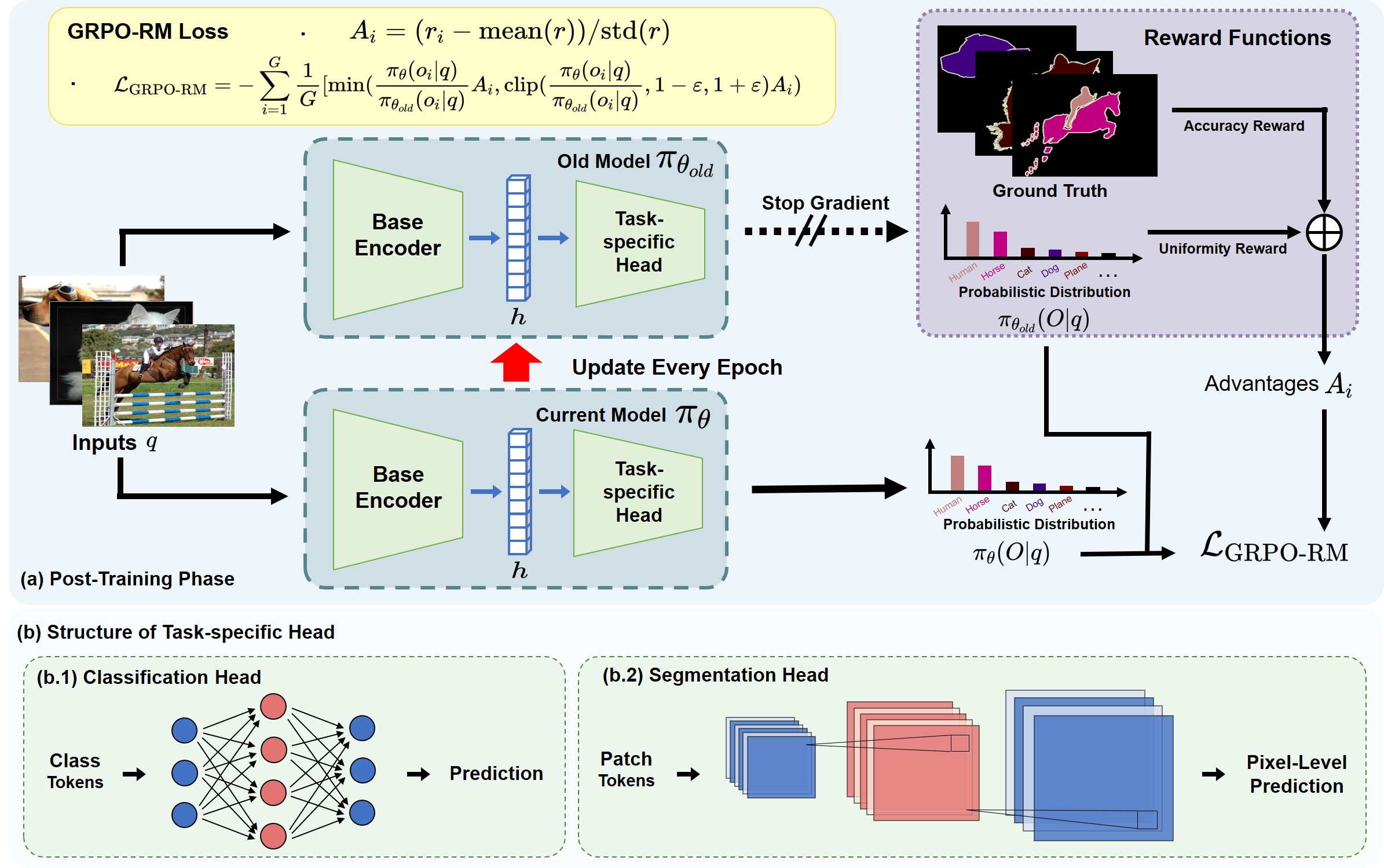
The framework of GRPO-RM. It illustrates the pipeline: Input Image -> DINOv2 -> Feature Embeddings -> Output Group Generation (via Softmax) -> Advantage Computation (Accuracy + Uniformity Rewards) -> Policy Optimization.
Evaluation Highlights
- Achieves an average 4.26% accuracy improvement on out-of-distribution datasets compared to standard fine-tuning
- Significantly outperforms standard fine-tuning on diverse tasks including image classification (CIFAR, ImageNet) and semantic segmentation (Pascal VOC)
- Demonstrates effective generalization of LLM-based RL techniques to non-generative visual backbones (DINOv2)
Breakthrough Assessment
7/10
Novel adaptation of a trending LLM technique (GRPO) to computer vision. Shows significant OOD gains, though the methodology is a straightforward translation of concepts rather than a fundamental theoretical shift.