📝 Paper Summary
Reinforcement Learning from Verifier Rewards (RLVR)
Mathematical Reasoning
Scaf-GRPO overcomes the 'learning cliff' in reasoning tasks by injecting hierarchical, minimal hints into prompts only when models plateau, restoring gradient signals without breaking on-policy consistency.
Core Problem
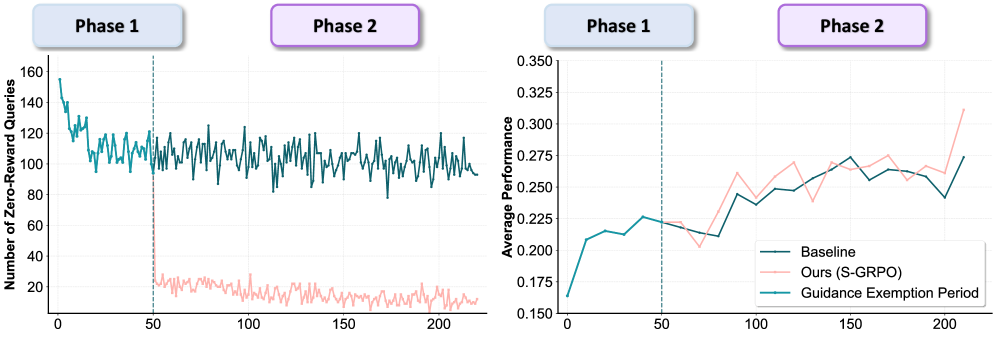
In RLVR, when models face problems far beyond their capabilities, they receive persistent zero rewards, causing the advantage signal to collapse to zero and halting learning (the 'learning cliff').
Why it matters:
- Difficult problems become invisible to the optimization process because zero variance in rewards yields zero gradients
- Existing solutions like prefix-forcing (teacher forcing) create distributional mismatches between teacher prefixes and student continuations
- Rigid guidance stifles exploration, preventing models from discovering novel or more efficient reasoning paths
Concrete Example:
When a model consistently fails a hard math problem (e.g., AIME 2024 #7), standard GRPO calculates zero advantage because all sampled outputs are incorrect. The model ignores this problem entirely. Scaf-GRPO detects this stagnation and injects a hint (e.g., 'Use Euler's Totient Theorem') into the prompt, allowing the model to generate a correct solution and restore a non-zero gradient.
Key Novelty
Scaffolded Group Relative Policy Optimization (Scaf-GRPO)
- Diagnoses 'true-hard' problems where the model stagnates, distinguishing them from 'pseudo-hard' problems the model can solve with more training
- Applies on-policy intervention by augmenting the rollout buffer with a successful trajectory generated via minimal, hierarchical hints (Knowledge → Planning → Solution)
- Maintains policy consistency by conditioning both the current and old policies on the hint-augmented prompt, avoiding importance sampling instability
Architecture
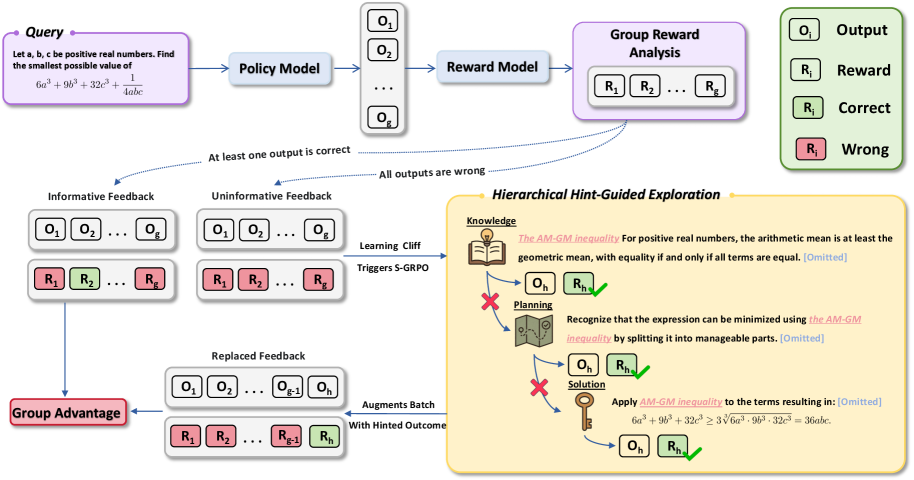
The Scaf-GRPO framework workflow, detailing the transition from standard exploration to hint-guided intervention.
Evaluation Highlights
- +44.3% relative improvement on AIME24 pass@1 score using Qwen2.5-Math-7B compared to vanilla GRPO baseline
- +12.6% relative improvement over vanilla GRPO on average across multiple math benchmarks (GSM8K, MATH, AIME24, AMC23)
- +9.2% relative gain over LUFFY, a strong prefix-based guidance method, demonstrating the superiority of hint-based scaffolding over rigid solution prefixes
Breakthrough Assessment
8/10
Strong theoretical grounding in overcoming the zero-reward problem while preserving on-policy stability. Significant empirical gains on hard benchmarks (AIME) validate the approach against strong baselines.