📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Reinforcement Learning (RL) for Reasoning
GRPO-CARE improves multimodal reasoning by replacing strict KL penalties with a group-relative consistency bonus that rewards reasoning chains that are both accurate and logically aligned with a stable reference model.
Core Problem
Standard outcome-supervised RL (like GRPO) improves final answer accuracy but often degrades reasoning coherence, as models find shortcut solutions that are correct but logically inconsistent.
Why it matters:
- Optimization for final answers alone encourages 'Thought Collapse' or shortcut learning, where reasoning does not actually support the conclusion
- Strict KL divergence penalties in standard RL overly constrain exploration, preventing the model from finding new, valid reasoning paths that differ from the pre-trained prior
- Existing benchmarks for MLLM post-training lack rigorous generalization tiers (in-distribution vs. out-of-distribution) needed to evaluate true reasoning robustness
Concrete Example:
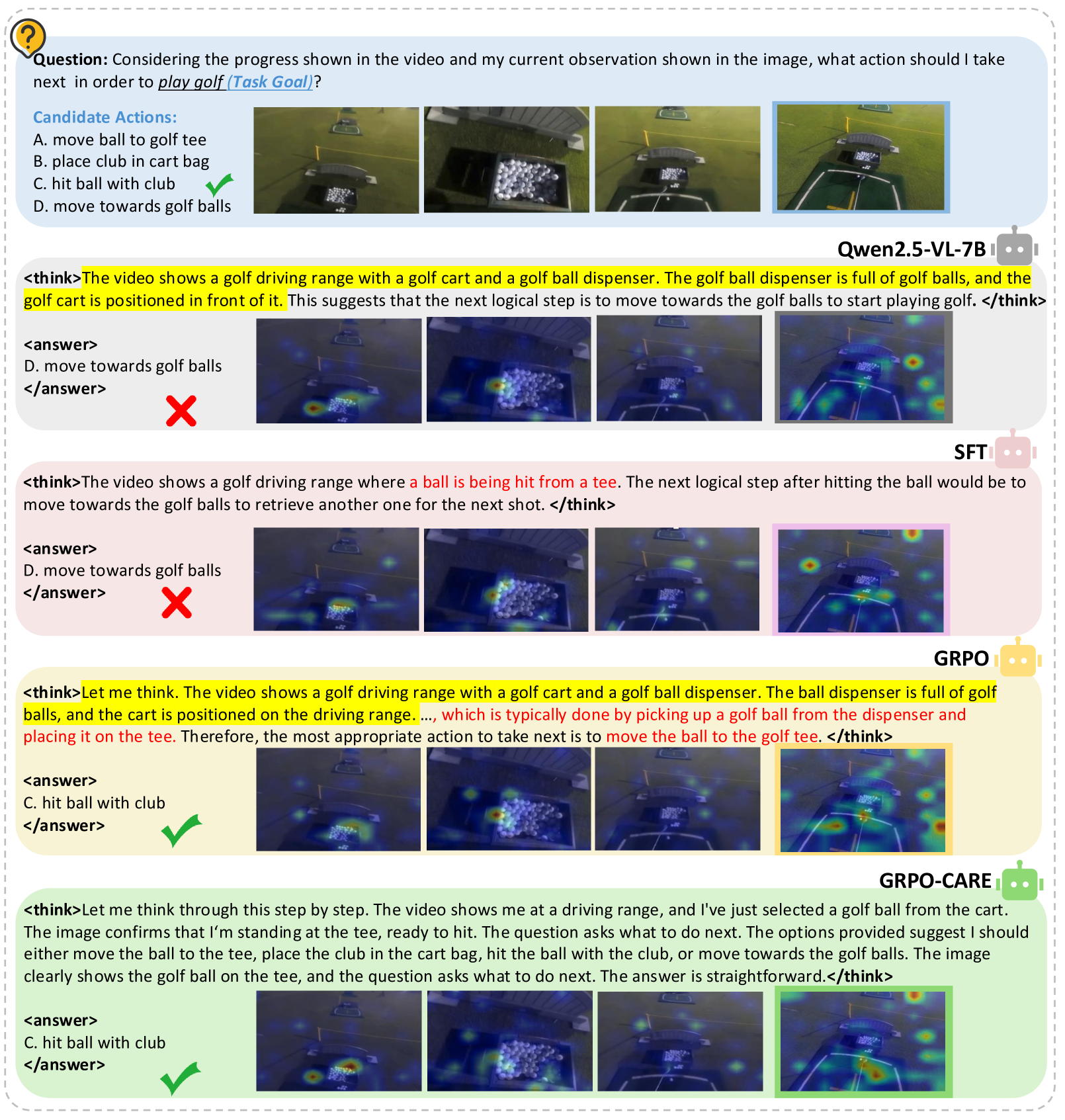
In a video task, a standard GRPO model correctly answers 'hit ball with club' but its reasoning chain confusingly suggests 'move the ball to the golf tee', contradicting the final action. GRPO-CARE aligns the reasoning to correctly identify the 'hit' action dynamics.
Key Novelty
Consistency-Aware Reward Enhancement (CARE) without process supervision
- Replaces the standard KL divergence penalty with an adaptive consistency bonus derived from a slowly updating reference model (EMA)
- Calculates a 'reasoning-to-answer' likelihood score: the reference model checks if the generated reasoning trace logically leads to the correct answer
- Applies a sparse reward bonus only to samples that are both accurate and demonstrate higher logical consistency than their group peers
Architecture
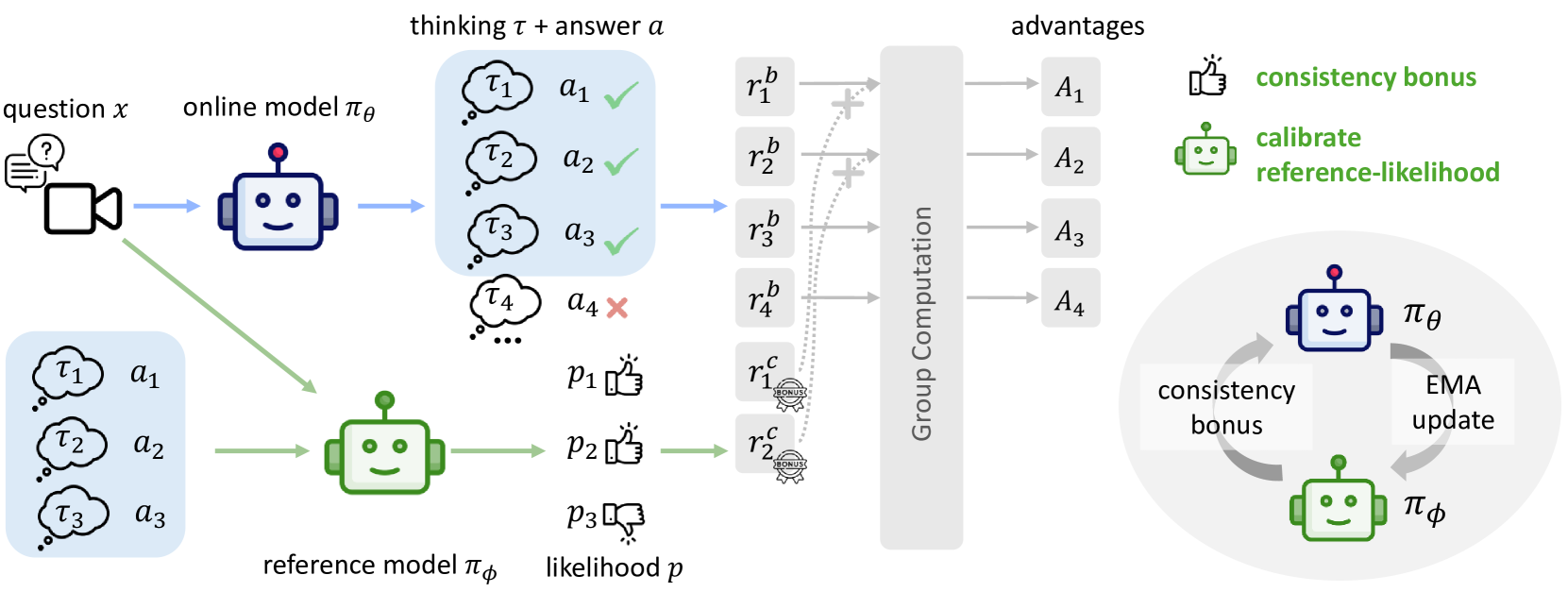
The GRPO-CARE framework pipeline showing the dual-reward mechanism (Outcome Reward + Consistency Bonus) and the reference model interaction.
Evaluation Highlights
- +6.7% accuracy improvement on the hardest out-of-distribution level (Level-3) of SEED-Bench-R1 compared to standard GRPO
- +24.5% increase in reasoning-answer consistency rate compared to standard GRPO
- Achieves strong transfer performance on general video benchmarks like MVBench (+3.6%) and EgoPlan (+3.4%)
Breakthrough Assessment
8/10
Significant methodology improvement for MLLM post-training by addressing the 'correct answer, wrong reasoning' problem without expensive process supervision. Also contributes a substantial, hierarchically structured benchmark.