📝 Paper Summary
Physics-Informed Machine Learning
LLM Alignment
Knowledge Graphs
PKG-DPO integrates Physics Knowledge Graphs into Direct Preference Optimization to force Large Language Models to respect physical laws and constraints during generation.
Core Problem
Standard preference optimization (DPO) aligns models with human quality perception but fails to enforce strict physical constraints, leading to plausible-sounding but physically invalid or dangerous outputs.
Why it matters:
- In high-stakes fields like welding, physically invalid recommendations (e.g., sub-melting-point temperatures) can cause structural failures and safety hazards
- Existing methods struggle when expert domain knowledge contradicts general human preferences, leading to fluent but scientifically incorrect reasoning
- Traditional LLMs lack mechanisms to validate outputs against conservation laws and safety thresholds in multi-physics environments
Concrete Example:
In welding engineering, a standard LLM might suggest parameters that look reasonable but violate thermodynamic limits (e.g., sub-melting-point temperatures) or safety rules (e.g., excessive current densities), which are physically impossible or dangerous.
Key Novelty
Physics-Grounded Direct Preference Optimization (PKG-DPO)
- Augments standard preference pairs with physics-violation penalties and reasoning rewards derived from a structured Physics Knowledge Graph (PKG)
- Uses a Physics Reasoning Engine to traverse the graph and validate candidate responses against explicit conservation laws and equations before optimization
- Modifies the DPO loss function to jointly optimize for human preference alignment and strict physics compliance
Architecture
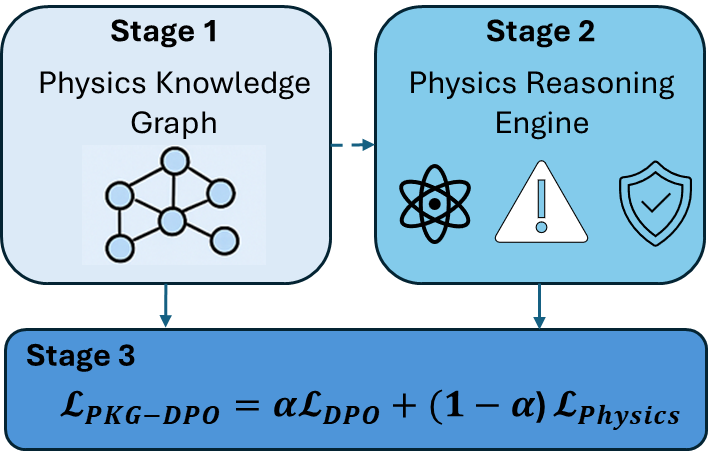
The three-stage framework of PKG-DPO: Graph Construction, Reasoning Engine, and Optimization.
Evaluation Highlights
- Achieves 17% fewer constraint violations (CVR) compared to KG-DPO (knowledge graph baseline) on welding tasks
- Improves Physics Score by 11% (0.89 vs 0.80) over KG-DPO, indicating better adherence to physical principles
- Demonstrates 12% higher Relevant Parameter Accuracy (RPA) than KG-DPO, showing more precise use of physics equations and constants
Breakthrough Assessment
7/10
Strong application of neuro-symbolic ideas to DPO for safety-critical domains. While domain-specific (welding), the methodology of enriching DPO with graph-based constraints is a significant step for reliable scientific AI.
