📝 Paper Summary
Offline Reinforcement Learning
Preference Optimization
LLM Alignment
This study benchmarks DPO variants to demonstrate their efficacy without supervised fine-tuning and introduces Preference Pruning to statistically select optimal training data configurations.
Core Problem
Aligning LLMs via Direct Preference Optimization (DPO) typically relies on expensive Supervised Fine-Tuning (SFT) and preference ranking, with unclear guidelines on dataset scaling and variant performance.
Why it matters:
- Ranking preferences using humans or GPT-4 is time-consuming and cost-intensive
- Standard alignment pipelines require a preliminary SFT stage, increasing computational overhead
- Current methods struggle with overfitting and lack comprehensive comparisons across domains like reasoning versus creative writing
Concrete Example:
When aligning a model for code generation, standard DPO might degrade performance if not carefully tuned with SFT, whereas variants like IPO might work directly on the base model, but practitioners lack data on which method works best per domain.
Key Novelty
Preference Pruning (PP) and SFT-Free Alignment Analysis
- Investigates whether alignment methods like IPO and KTO can function effectively without the standard Supervised Fine-Tuning (SFT) warm-up stage
- Introduces Preference Pruning (PP): a statistical method that selects generation temperatures for 'chosen' vs 'rejected' pairs by analyzing BLEU/ROUGE score distributions rather than performing expensive full evaluations
Architecture
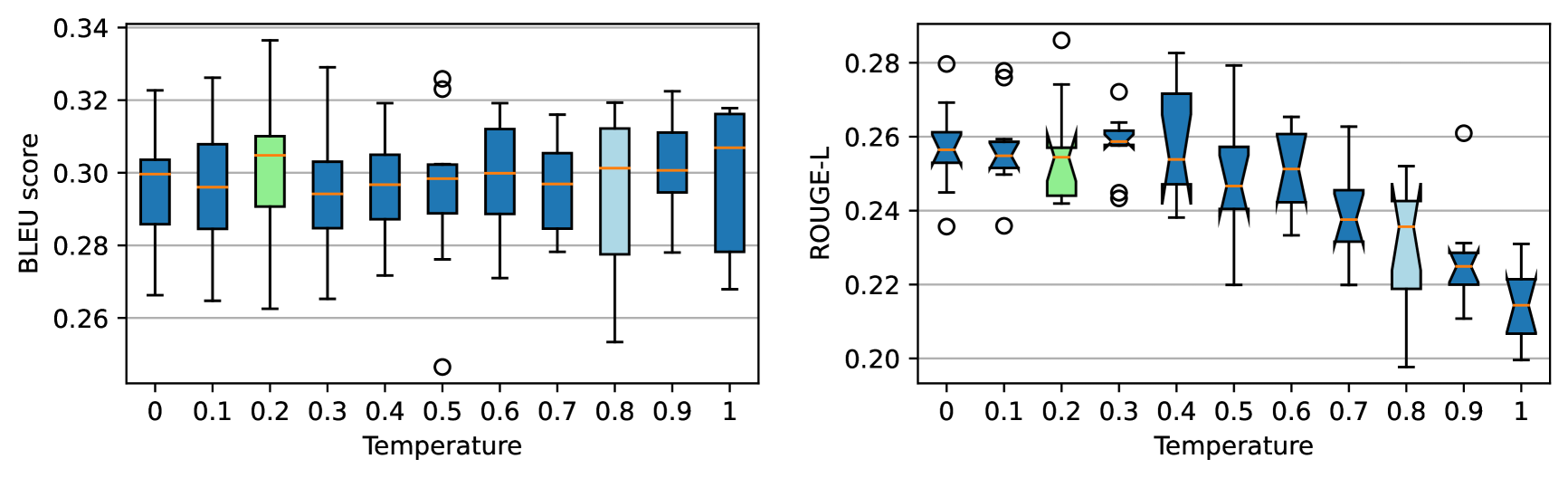
Analysis of BLEU and ROUGE-L scores across different generation temperatures to justify Preference Pruning.
Evaluation Highlights
- UltraChat dataset (200k examples) used for SFT baselines to establish high-quality references
- UltraFeedback-binarized dataset (63k pairs) used for training alignment models
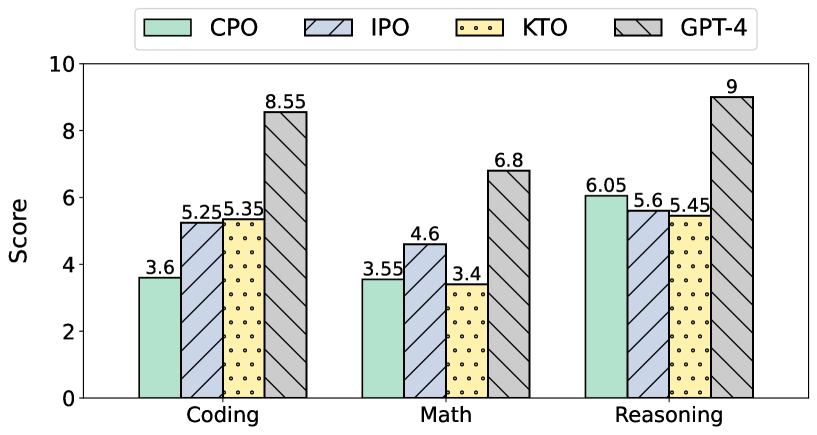
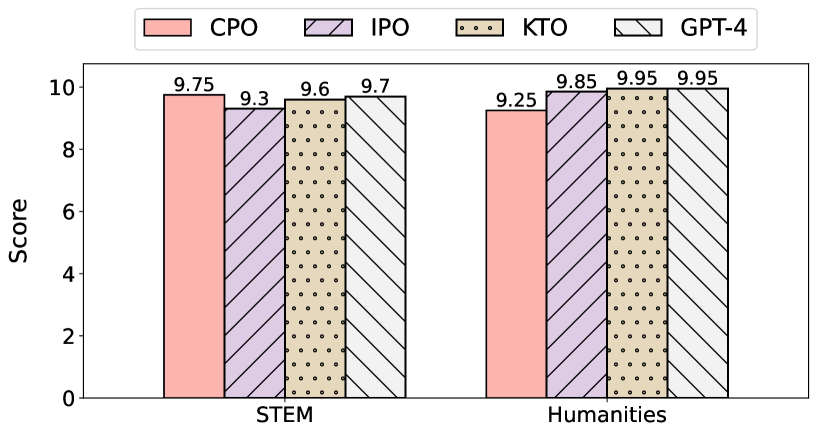
- Qualitative finding: IPO and KTO variants demonstrate performance comparable to SFT models even without the SFT warm-up stage [numeric scores not reported in text]
Breakthrough Assessment
5/10
Provides a useful empirical benchmark and a cost-saving heuristic (Preference Pruning), but primarily analyzes existing methods (DPO, IPO, KTO) rather than proposing a fundamental algorithmic breakthrough.