📊 Experiments & Results
Evaluation Setup
Safety alignment evaluation using jailbreaking prompts and general capability benchmarks
Benchmarks:
- AdvBench (Safety/Jailbreaking)
- ARC (Reasoning)
- HellaSwag (Commonsense Reasoning)
- MMLU (Multi-task Language Understanding)
- TruthfulQA (Truthfulness)
Metrics:
- Attack Success Rate (ASR)
- General Task Accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Numeric results tables are not included in the provided text snippet. The paper reports that Self+RM achieves the lowest ASR (safest) while maintaining comparable general capability scores. Specific numeric deltas are unavailable in the source text. | ||||
Experiment Figures
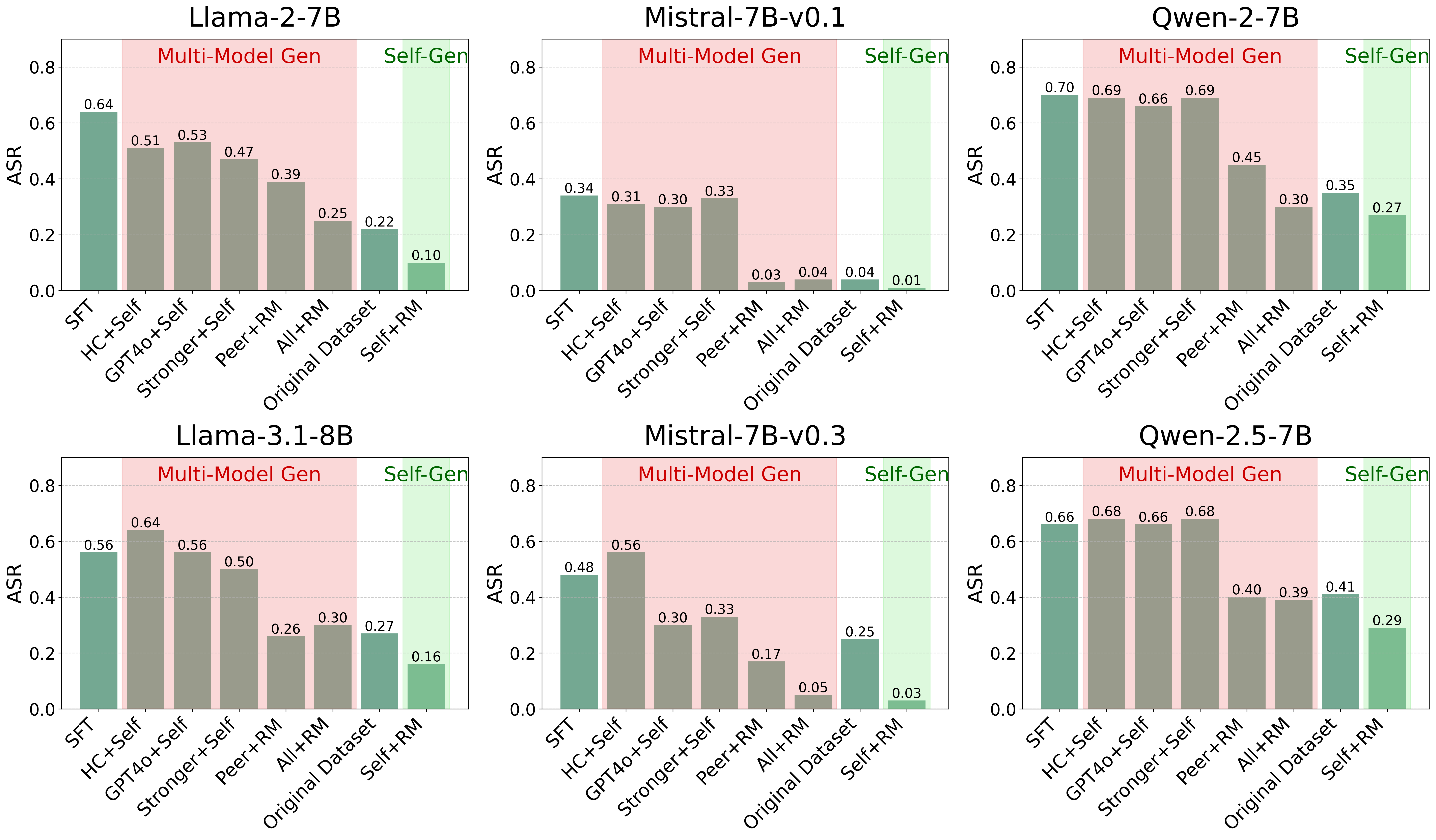
Comparison of Attack Success Rate (ASR) across different preference data construction methods (Self+RM vs Multi-model approaches)
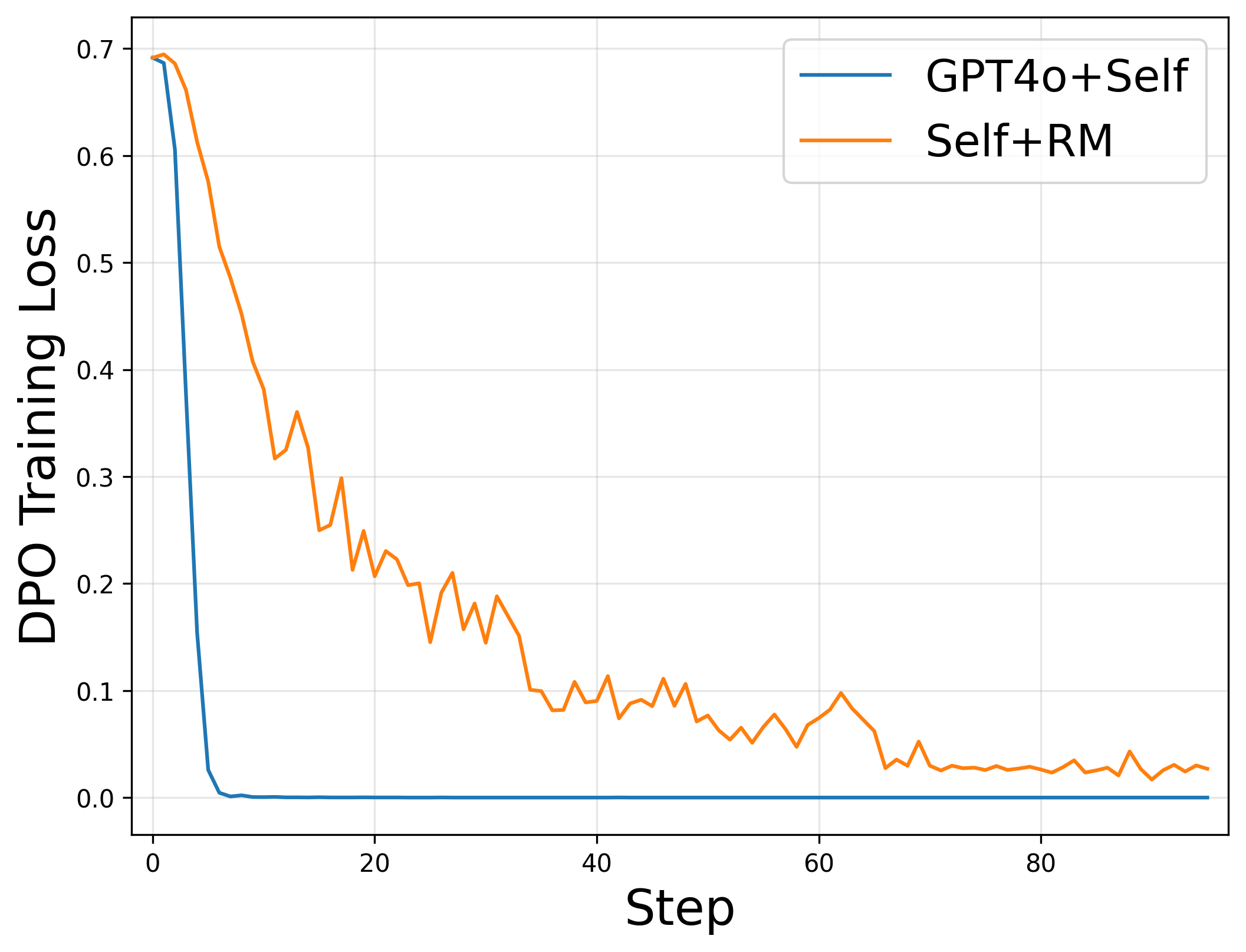
Analysis of training dynamics: (a) DPO training loss curves, (b) Linear separability scores, (c) ASR vs Linear Loss correlation
Main Takeaways
- Self-generated preference data (Self+RM) significantly outperforms multi-model data (including GPT-4o generated) in safety alignment, achieving the lowest Attack Success Rates (ASR) across multiple model families.
- Using stronger models (GPT-4o) as 'chosen' responses leads to rapid loss convergence but poor safety generalization, a symptom of reward hacking where the model learns style over substance.
- There is a non-linear relationship between the linear separability of preference data and safety: 'moderate' separability (Self+RM) is optimal, while 'high' separability (GPT-4o+Self) allows the model to exploit superficial shortcuts.
- General capabilities (MMLU, ARC, etc.) are largely unaffected by the choice of safety data source; Self+RM performs comparably to multi-model methods on non-safety tasks.