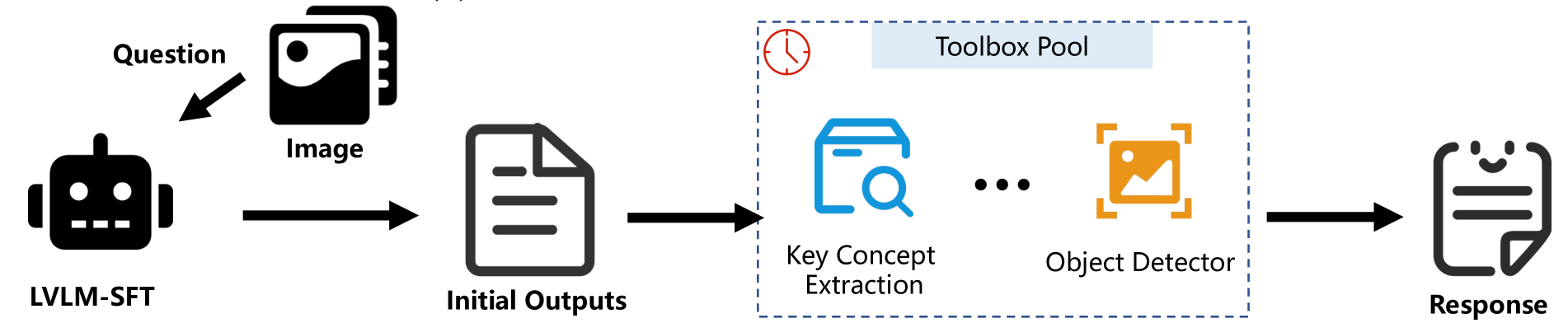
📊 Experiments & Results
Evaluation Setup
Assessment of multimodal hallucination and general performance capabilities.
Benchmarks:
- POPE (Object Existence Evaluation (Hallucination))
- MME (Comprehensive Multimodal Evaluation)
- SHR (Sentence-level Hallucination Ratio) [New]
Metrics:
- Accuracy (POPE)
- Score (MME)
- Sentence-level Hallucination Ratio (SHR)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Application of HA-DPO to MiniGPT-4 yields substantial improvements in both hallucination metrics and general multimodal capabilities. | ||||
| POPE | Accuracy | 51.13 | 86.13 | +35.00 |
| MME | Score | 932.00 | 1326.46 | +394.46 |
Experiment Figures
Comparison of data distribution and sentence fluency during training with and without style consistency.
Main Takeaways
- HA-DPO significantly reduces hallucination rates (POPE) while simultaneously improving general model performance (MME), suggesting that reducing hallucinations improves overall grounding.
- Style consistency in the DPO dataset is critical; without it, models may suffer from 'preference collapse' or loss of fluency (repeating words) during training.
- The proposed data pipeline (Generation -> Correction -> Style Augmentation) effectively creates high-quality preference pairs without human annotation.