📝 Paper Summary
Mathematical Reasoning
Data Selection for LLMs
SAI-DPO improves mathematical reasoning by iteratively selecting training data that aligns with the model's current self-aware difficulty and specifically targets knowledge points where the model is failing.
Core Problem
Existing data selection methods rely on static, external difficulty metrics that fail to adapt to a model's evolving capabilities and specific weaknesses during iterative training.
Why it matters:
- Static metrics result in training on data that is either too easy (wasteful) or too hard (ineffective) as the model improves
- Current approaches ignore the specific knowledge gaps of the model, treating all errors equally rather than targeting structural weaknesses
- Training reasoning models is resource-intensive; improving data efficiency is critical for developing powerful models with constrained resources
Concrete Example:
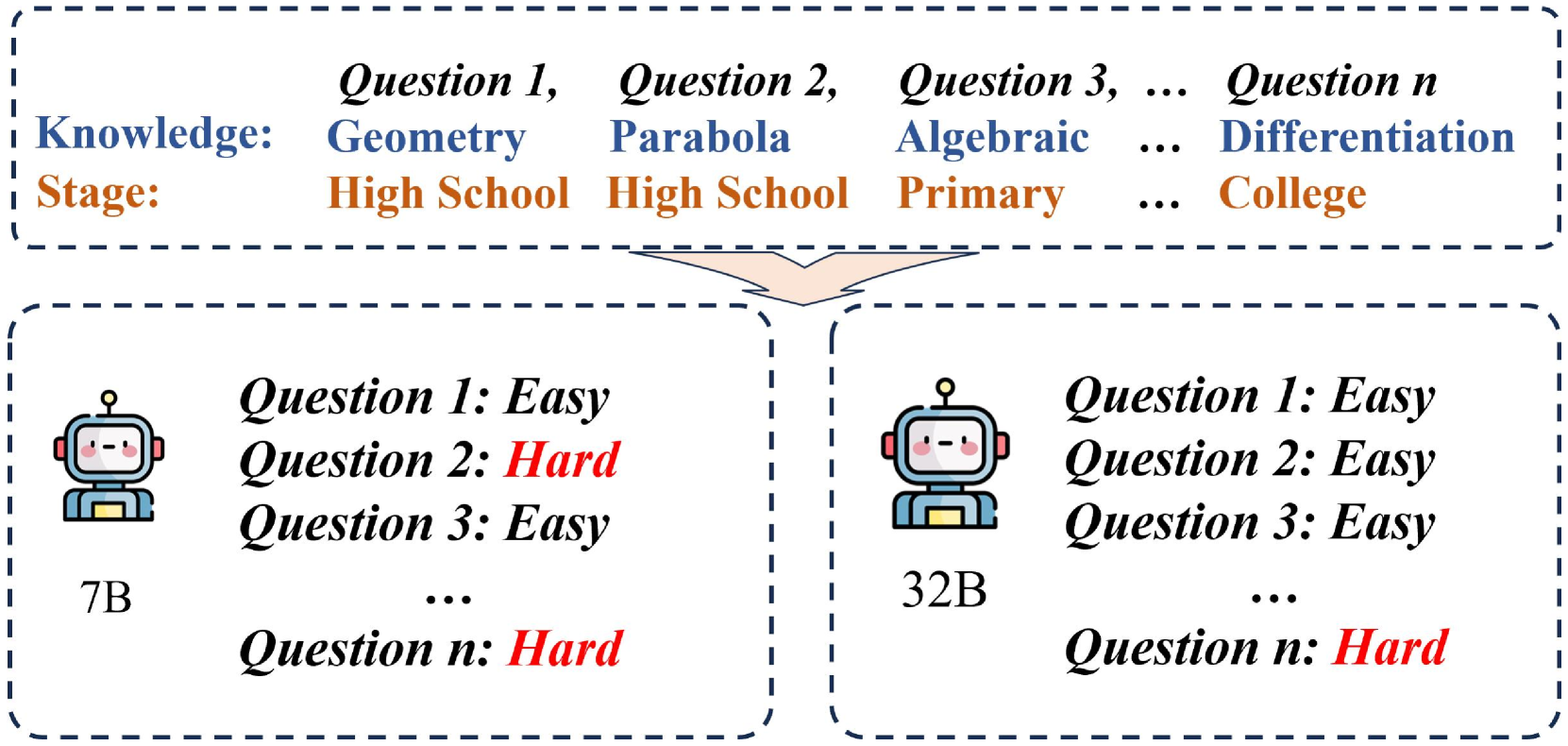
A model might be proficient in algebra but weak in geometry. A static sampler continues to feed it algebra problems it has already mastered, while a difficulty-blind sampler might feed it geometry problems that are impossibly hard, rather than those on the 'frontier' of its capability.
Key Novelty
Self-Aware Iterative Direct Preference Optimization (SAI-DPO)
- defines 'Self-Aware Difficulty' using the model's own performance (Pass@K) and generation characteristics (step count, length) rather than external labels
- Uses 'Knowledge Points Similarity' to cluster questions and dynamically up-weight clusters where the model currently fails, ensuring training focuses on active weaknesses
Architecture
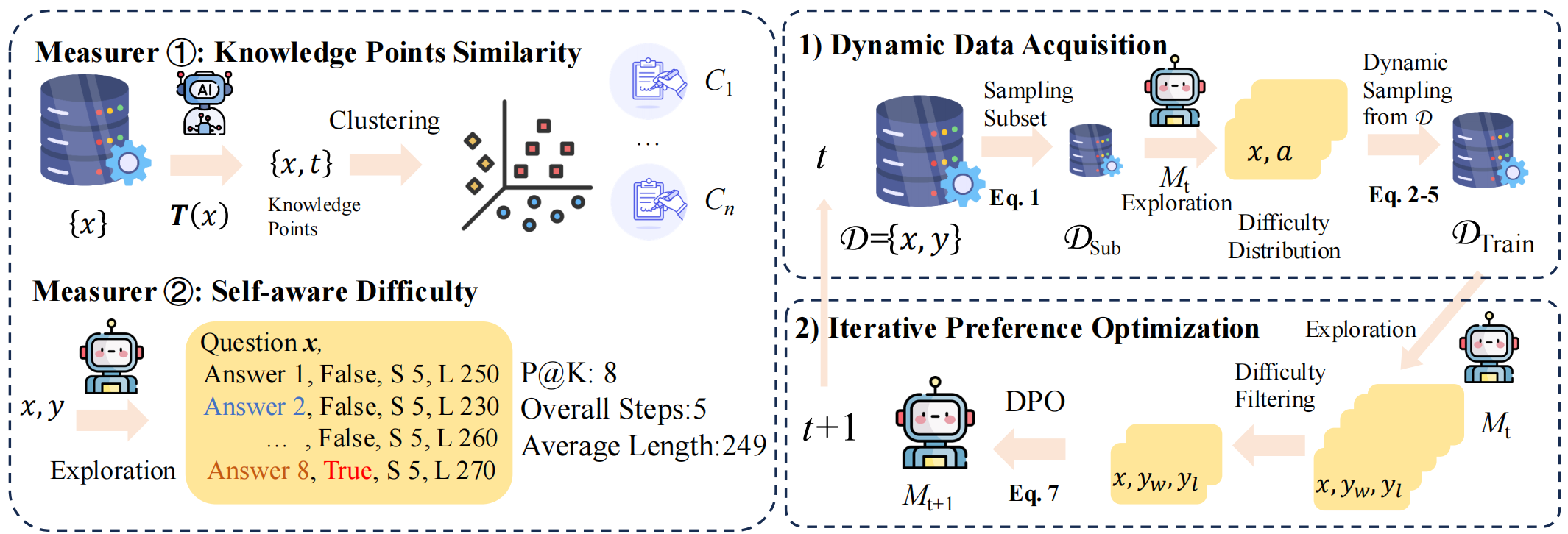
Overview of the SAI-DPO pipeline, illustrating the offline data preparation and the online iterative loop of probing, dynamic sampling, and training.
Evaluation Highlights
- Achieves an average performance boost of up to 21.3 percentage points across 8 mathematical reasoning benchmarks
- +15 percentage points improvement on AMC23 (American Mathematics Competitions) compared to baselines
- +10 percentage points improvement on AIME24 (American Invitational Mathematics Examination) compared to baselines
Breakthrough Assessment
7/10
Strong empirical gains (+21.3%) on hard math benchmarks suggest the dynamic sampling strategy is highly effective, though the core components (DPO, clustering, P@K) are established techniques combined in a novel loop.