📝 Paper Summary
LLM Alignment
Direct Preference Optimization (DPO)
Safety Fine-tuning
DPO-Kernels improves model alignment by replacing standard probability-based objectives with a hybrid loss that uses kernel methods and alternative divergences to capture semantic and geometric data relationships.
Core Problem
Standard Direct Preference Optimization (DPO) relies on a rigid KL divergence constraint and simple probability ratios, which fails to capture complex semantic relationships and can be unstable during training.
Why it matters:
- Fixed divergence measures like KL often lead to instability or mode collapse when the reference and policy distributions differ significantly
- Probability-based contrastive loss ignores the semantic quality of responses, potentially reinforcing high-probability but semantically poor outputs
- Single-kernel approaches (like standard DPO, effectively a linear kernel) cannot model complex decision boundaries needed for tasks like safety alignment or reasoning
Concrete Example:
In safety fine-tuning, standard DPO might fail to clearly separate 'safe' and 'unsafe' responses if they share similar statistical patterns. DPO-Kernels using an RBF kernel projects these into a high-dimensional space where 'unsafe' inputs are clustered tightly in a null space, creating a distinct decision boundary.
Key Novelty
DPO-Kernels (Kernelized Hybrid Loss & Hierarchical Mixture)
- Integrates 'Hybrid Loss' which combines standard probability ratios with semantic embedding similarities, ensuring preferences reflect both likelihood and meaning
- Applies Kernel Methods (Polynomial, RBF, Spectral, Mahalanobis) to the loss function, allowing the model to optimize preferences in a richer, non-linear feature space
- Introduces Hierarchical Mixture of Kernels (HMK) to dynamically balance local kernels (fine details) and global kernels (broad patterns) during training to prevent kernel collapse
Architecture
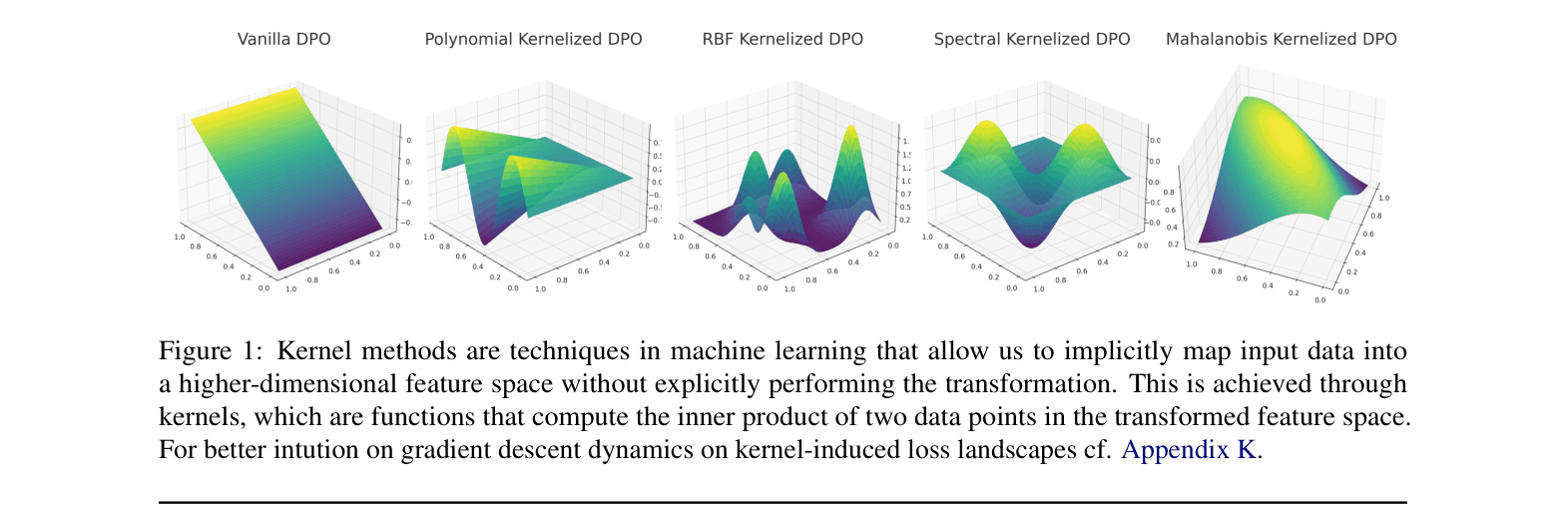
Conceptual visualization of how different kernels (Polynomial, RBF, Spectral, Mahalanobis) transform the loss landscape and the effective range of the Hierarchical Mixture of Kernels (HMK).
Evaluation Highlights
- +16% improvement in overall F1 Score across 12 datasets using HMK (Hierarchical Mixture of Kernels) compared to standard DPO (0.94 vs. 0.78)
- Achieves near-perfect Safety alignment scores (0.98 F1) using HMK, compared to 0.66 for standard DPO, by effectively clustering unsafe inputs
- Demonstrates robust generalization with lower Weighted Alpha scores (HT-SR metric) compared to baselines, indicating reduced overfitting despite higher performance
Breakthrough Assessment
8/10
Significant methodological expansion of DPO. By integrating kernel methods and divergence alternatives, it addresses fundamental rigidity in current alignment techniques, backed by strong empirical gains across diverse tasks.