📝 Paper Summary
Multi-objective alignment
Steerable generation
MO-ODPO aligns a single language model to multiple conflicting user preferences by combining prompt-based weight conditioning with online Direct Preference Optimization, enabling dynamic inference-time steerability without retraining.
Core Problem
Aligning LLMs to diverse, conflicting human preferences (e.g., helpfulness vs. harmlessness) typically requires training separate models for each trade-off or using computationally expensive parameter merging at inference.
Why it matters:
- User preferences vary widely and change over time, making it infeasible to train a specialist policy for every possible combination of objective weights
- Existing offline methods suffer from distribution shift and overfitting, while parameter-based steering methods (souping) incur high computational costs during inference
- Current approaches struggle to provide fine-grained control over model behavior without sacrificing performance or efficiency
Concrete Example:
A user might require a summary that is '80% concise and 20% detailed', while another wants '20% concise and 80% detailed'. Standard methods force a single fixed trade-off (e.g., 50/50) or require loading completely different model weights for each user. MO-ODPO allows passing these weights in the prompt to a single model.
Key Novelty
Multi-Objective Online Direct Preference Optimization (MO-ODPO)
- Conditions a single policy on numerical preference weights inserted directly into the system prompt, allowing the model to 'read' the desired trade-off
- Uses an online training loop where the model generates its own responses, scores them against the current weights using multiple reward models, and updates via DPO to learn the Pareto frontier dynamically
Architecture
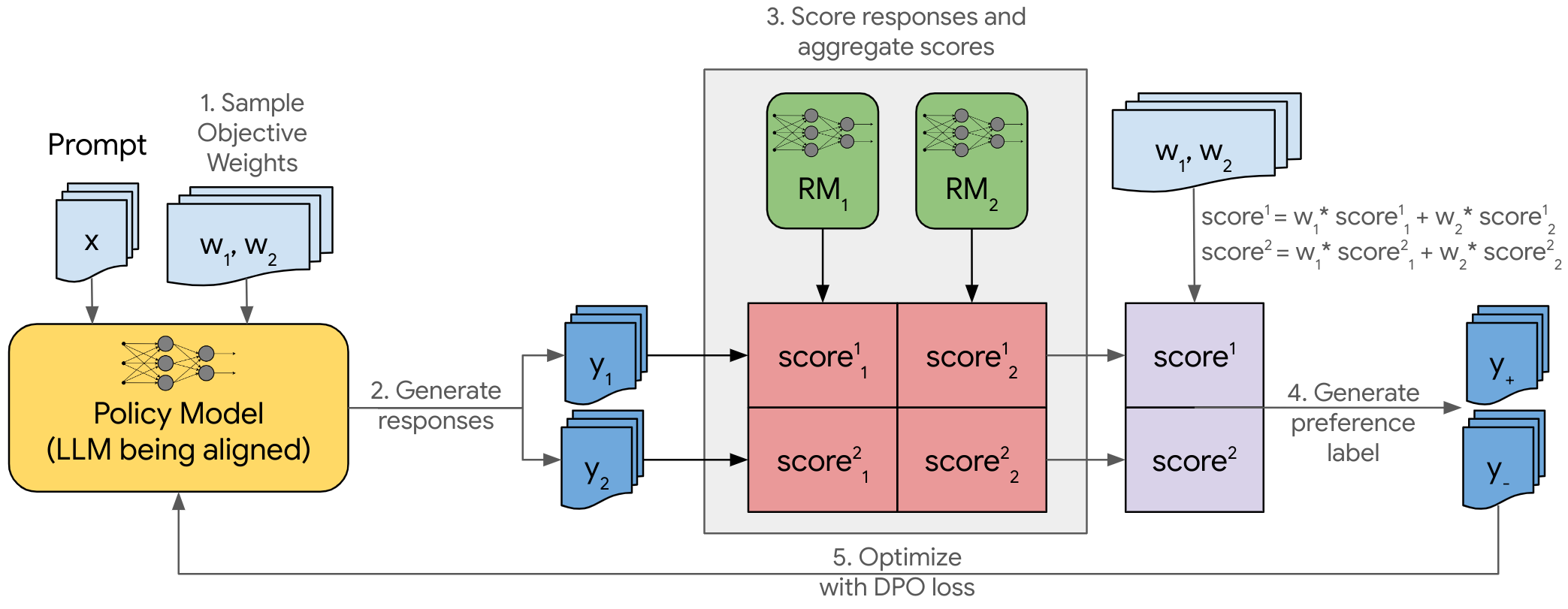
The training loop for a single step of MO-ODPO.
Breakthrough Assessment
7/10
Proposes a logical and efficient extension of Online DPO to multi-objective settings. While the components (DPO, prompt conditioning) exist, the combination addresses a critical efficiency gap in personalized alignment.