📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Hallucination Mitigation
Preference Optimization
DA-DPO mitigates overfitting in multimodal preference learning by estimating sample difficulty using pre-trained vision-language models and dynamically reweighting the DPO objective to prioritize hard samples.
Core Problem
Standard DPO training for MLLMs overfits to 'easy' preference pairs where responses are clearly distinguishable, leading to degradation in general multimodal capabilities while failing to learn from harder, more nuanced examples.
Why it matters:
- MLLMs frequently 'hallucinate' non-existent visual details, limiting their reliability in factual applications
- Collecting high-quality manual preference data is labor-intensive, and automated data often contains imbalances between easy and hard samples
- Current methods that treat all preference pairs equally lead to suboptimal alignment and performance regression on general benchmarks
Concrete Example:
In a dataset, an 'easy' pair might contrast a correct caption with a completely irrelevant hallucination, while a 'hard' pair requires distinguishing fine-grained details. Standard DPO over-optimizes the easy pair (which the model already handles well) and neglects the hard one, failing to improve fine-grained reasoning.
Key Novelty
Difficulty-Aware Direct Preference Optimization (DA-DPO)
- Uses an ensemble of frozen, pre-trained models (CLIP and LLaVA) to estimate the 'difficulty' of each preference pair without any explicit supervision or extra training
- Introduces a dynamic scaling factor to the DPO objective that increases the regularization strength for easy samples (forcing the model to stay close to the reference) and relaxes it for hard samples (allowing more learning)
Architecture
The DA-DPO framework workflow: Difficulty Estimation followed by Difficulty-Aware Training.
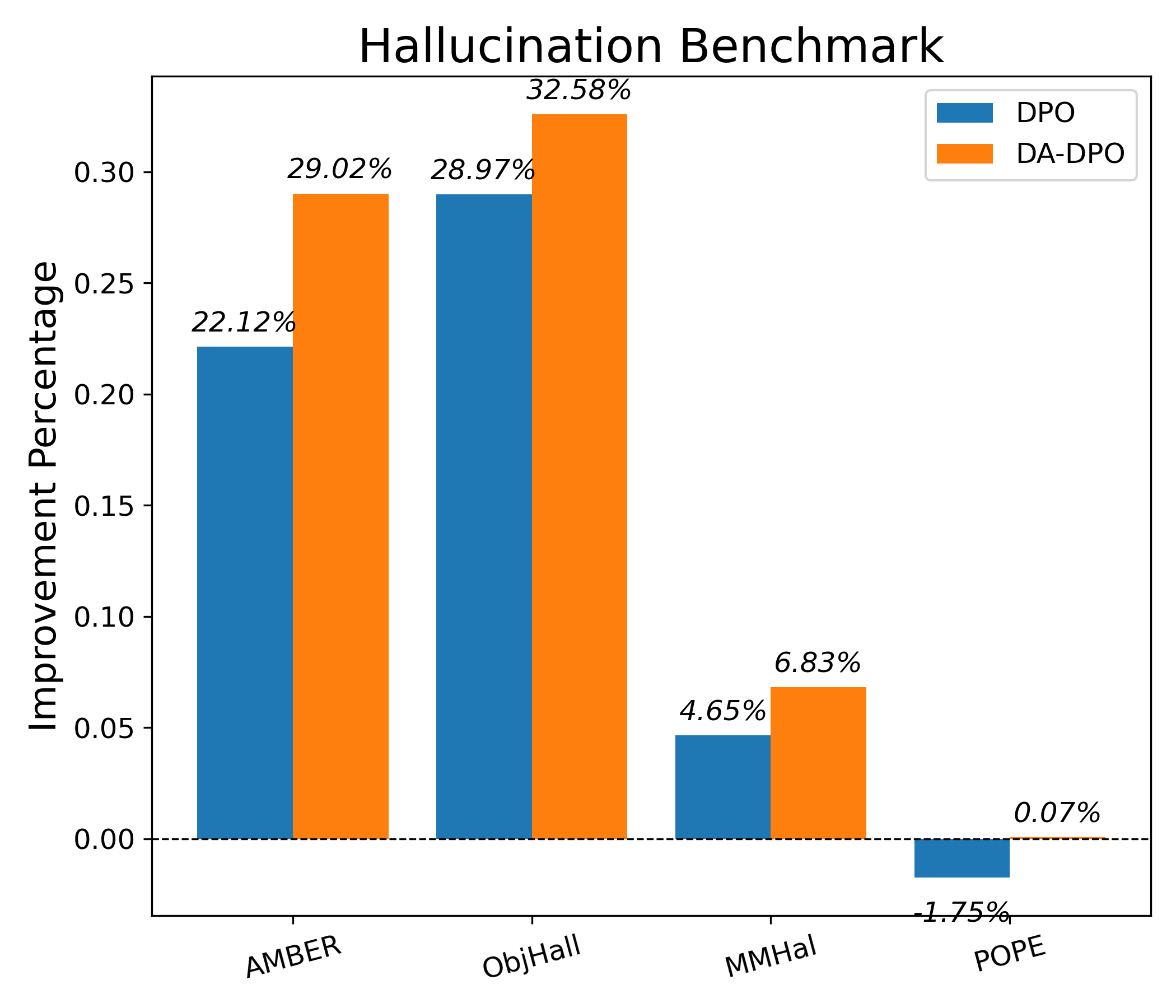
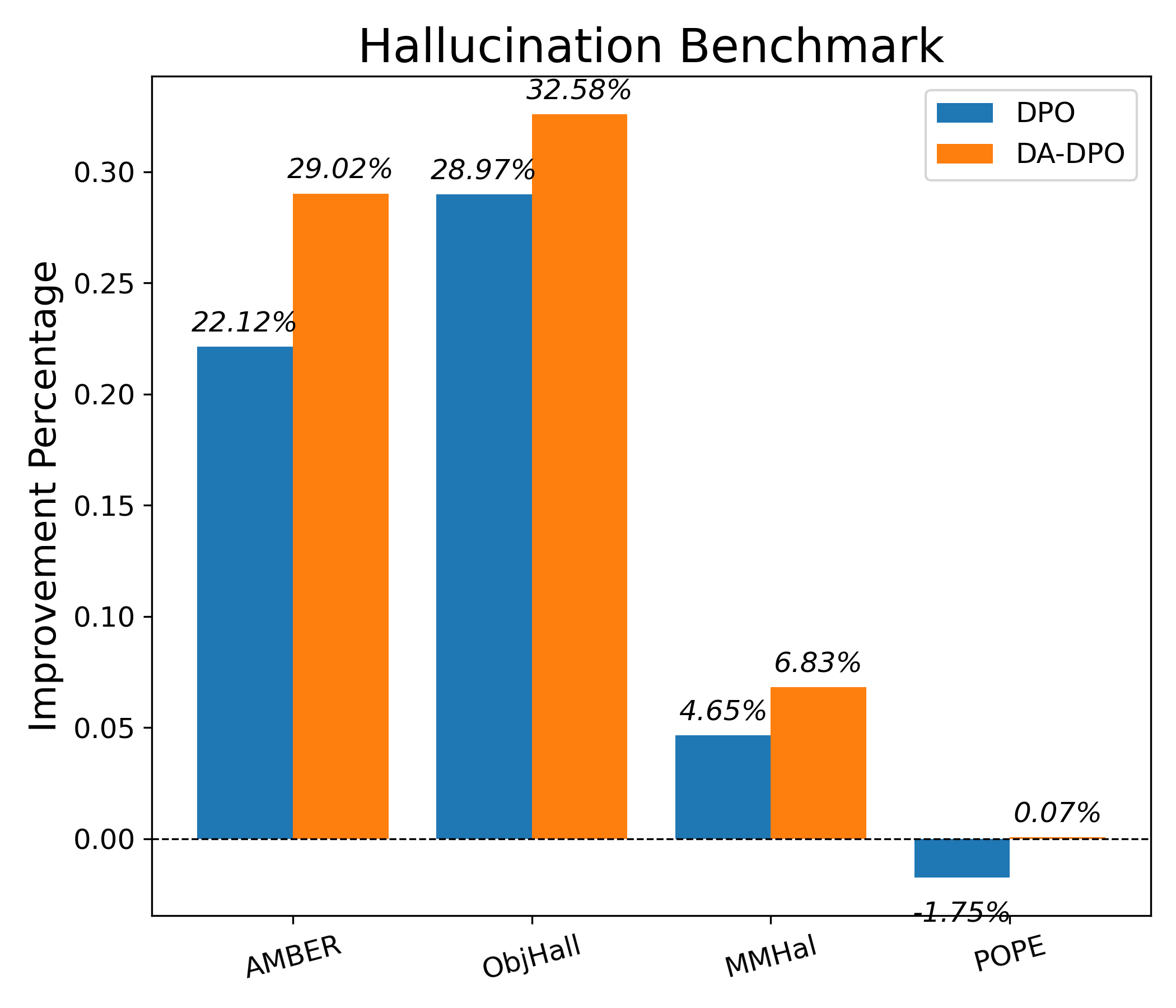
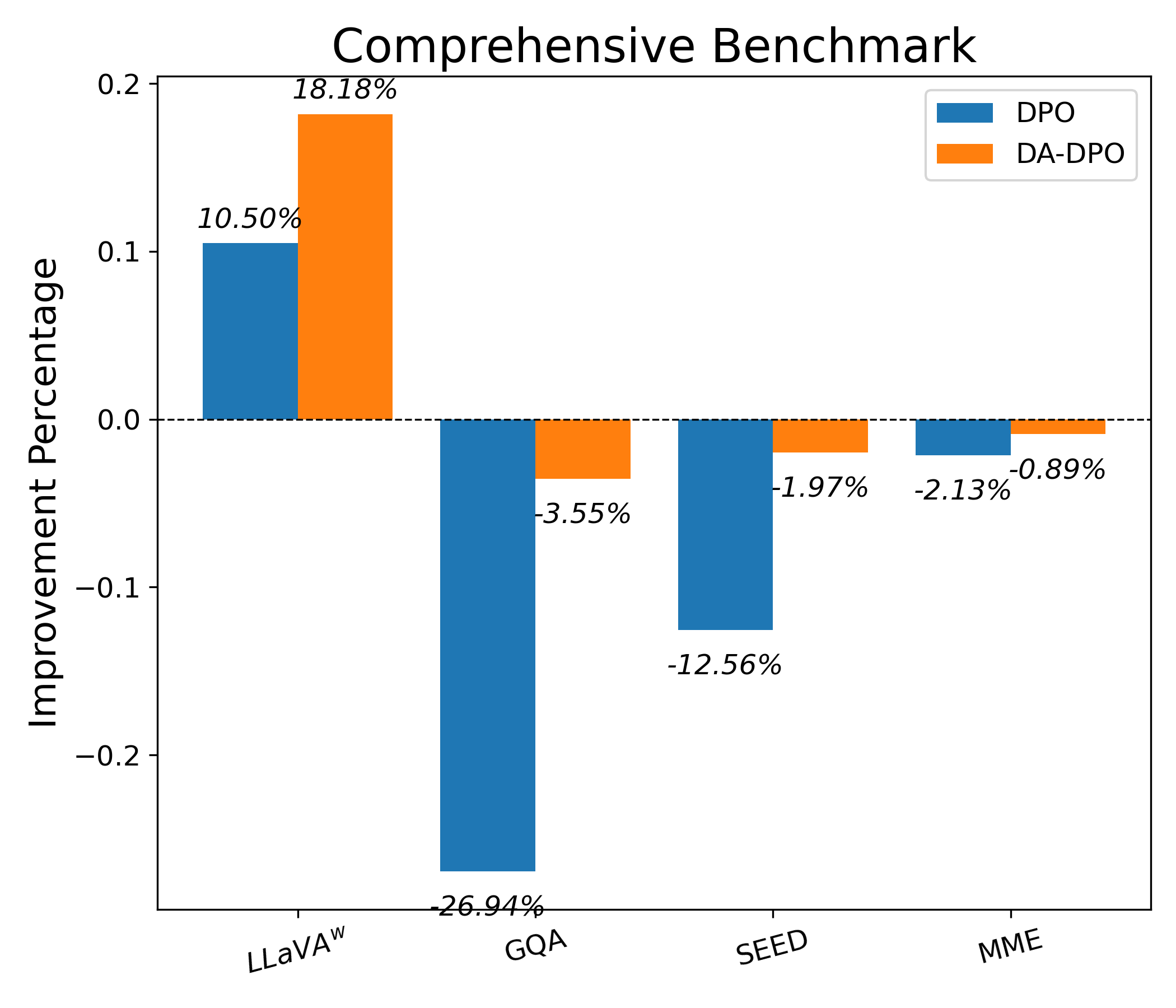
Evaluation Highlights
- Mitigates overfitting as measured by the Area Under Gap (AUG) between easy and hard sample rewards compared to vanilla DPO
- Demonstrates slower, more controlled reward growth on easy samples, indicating reduced over-optimization
- Consistent improvements reported on hallucination benchmarks (AMBER, Object HalBench) and general benchmarks (MME, SEED-Bench) across multiple model scales (LLaVA v1.5, LLaVA-OneVision)
Breakthrough Assessment
7/10
Addresses a specific, empirically validated overfitting issue in DPO with a clever, training-free difficulty estimation method. While an incremental modification to DPO, it offers practical efficiency gains.