📝 Paper Summary
Alt-text Generation
Multimodal Alignment
MCM-DPO improves alt-text generation by extending Direct Preference Optimization to include visual and contextual preference pairs, rather than optimizing solely on text responses.
Core Problem
Existing MLLMs produce verbose captions rather than concise alt-text, and supervised fine-tuning fails due to noisy, inconsistent user-generated annotations on social media.
Why it matters:
- 2.2 billion people have visual impairments, yet up to 98% of Twitter images lack alt-text, limiting access to digital content
- Standard MLLMs are biased toward image captioning (detailed descriptions) rather than the context-aware, functional summaries required for alt-text
- Reliance on Supervised Fine-Tuning (SFT) limits performance because manually cleaning large-scale noisy alt-text data is labor-intensive
Concrete Example:
A standard image captioning model might describe a Twitter image in excessive visual detail (e.g., 'A person standing next to a tree wearing a blue shirt...'), whereas a blind user requires concise, context-aware alt-text relevant to the tweet's post text.
Key Novelty
Multifaceted Cross-Modal Direct Preference Optimization (MCM-DPO)
- Extends standard DPO by constructing preference pairs not just for the text response, but also for the image (visual preference) and the surrounding context (contextual preference)
- Optimizes across seven distinct dimensions: single preferences (Response, Image, Context), pairwise combinations (e.g., Image+Response), and multi-preference (all three combined) to align modalities
- Utilizes negative samples for images (e.g., rotated images) and contexts (randomly swapped contexts) to teach the model to distinguish correct cross-modal alignment
Architecture
The MCM-DPO framework showing the seven preference optimization dimensions derived from image, context, and response combinations.
Evaluation Highlights
- Constructed TAlt and PAlt datasets comprising 202k annotated alt-text samples and 18k preference pairs from Twitter and Pinterest
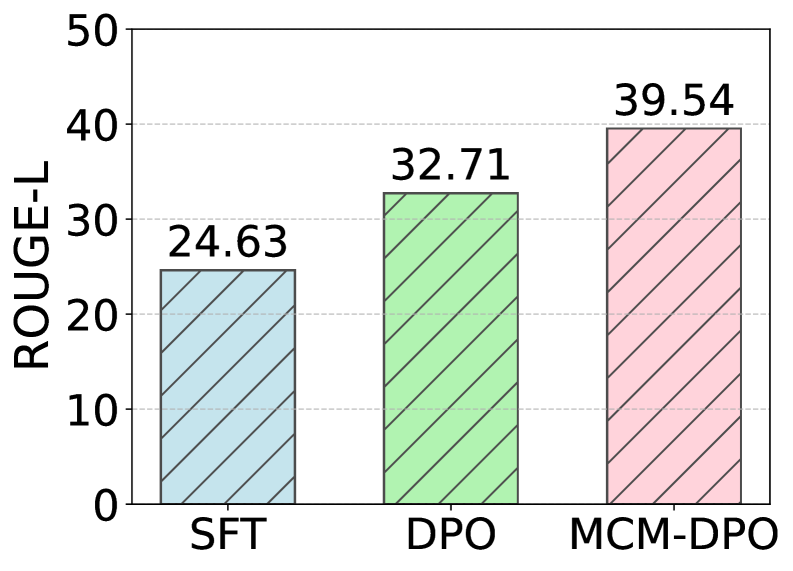
- Proposed MCM-DPO consistently outperforms both standard DPO and SFT baselines on TAlt and PAlt benchmarks (qualitative claim from abstract, specific numbers not in provided text)
- Establishes a new state-of-the-art performance for alt-text generation by reducing reliance on accurate target annotations
Breakthrough Assessment
7/10
Novel extension of DPO to non-text modalities (image/context inputs) addresses a specific, high-impact accessibility problem. The large-scale dataset contribution is significant.