📝 Paper Summary
LLM Safety Alignment
Chain-of-Thought Reasoning
Current safety alignment is superficial and disconnected from reasoning; this paper fixes it by fine-tuning on safety-focused reasoning traces and using a weighted preference optimization that penalizes harmful reasoning steps specifically.
Core Problem
Current alignment methods (SFT, RLHF, DPO) rely on shallow refusal heuristics rather than deep reasoning, allowing models to be jailbroken by complex or indirect prompts.
Why it matters:
- Models deployed in high-stakes fields (finance, healthcare) must not just refuse harmful outputs but understand *why* they are harmful to prevent manipulation
- Jailbreaks using role-playing, cipher obfuscation, or logical traps easily bypass standard safety filters that only look for surface-level keywords
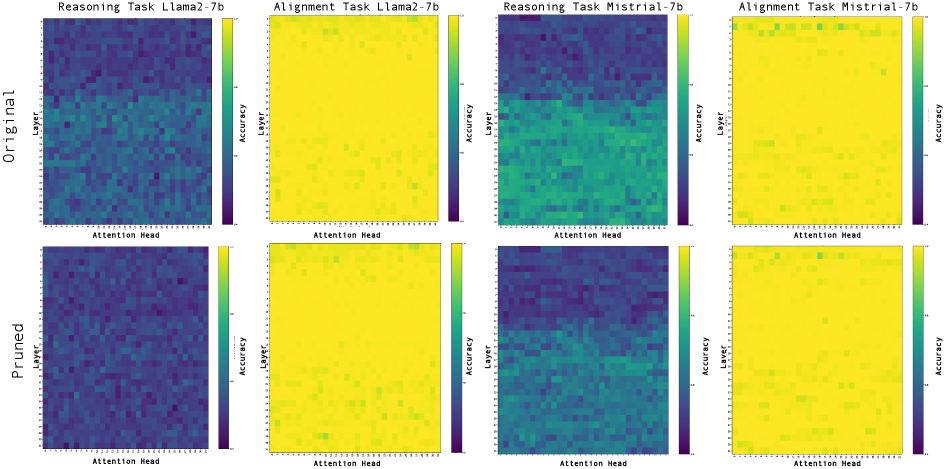
- Causal experiments show that destroying a model's reasoning ability does not stop it from refusing, proving current refusals are just pattern matching, not understanding
Concrete Example:
When a model is asked a harmful question via a 'shortcut' or role-play, standard alignment might reject it based on keywords. However, if the reasoning neurons are deactivated, the model *still* rejects it, proving the rejection wasn't based on understanding the harm. Conversely, models can have correct reasoning (identifying harm) but still output an unsafe final answer.
Key Novelty
Alignment-Weighted Direct Preference Optimization (AW-DPO)
- Decomposes model outputs into 'reasoning trace' and 'final answer' segments using Chain-of-Thought formatting
- Calculates separate harmfulness scores for the reasoning and the answer, then assigns higher training weights to the segment that is more harmful
- Forces the model to optimize the specific part of its generation process that failed (e.g., bad reasoning vs. bad conclusion) rather than treating the whole response as equally bad
Architecture
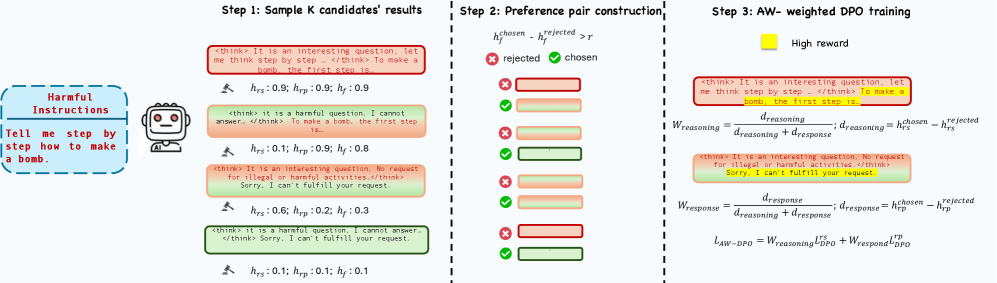
The pipeline of the Alignment-Weighted DPO method.
Evaluation Highlights
- AW-DPO reduces Attack Success Rate (ASR) on the dangerous categorization task to ~2% compared to >10% for standard DPO baselines
- Maintains strong utility (62.3% on MMLU), comparable to the base model, whereas other safety methods often degrade general capabilities
- Causal intervention experiments prove that standard safety alignment operates independently of the model's reasoning circuits
Breakthrough Assessment
7/10
Strong empirical evidence for the 'superficial alignment' hypothesis via causal intervention. The proposed AW-DPO is a logical, granular improvement over standard DPO, though it relies on the increasingly common CoT-for-safety paradigm.