📝 Paper Summary
LLM Safety Alignment
Constrained Optimization
Reinforcement Learning from Human Feedback (RLHF)
PD-DPO is a constrained alignment method that fine-tunes LLMs to maximize helpfulness while satisfying safety constraints by training only two models instead of the standard three.
Core Problem
Existing constrained alignment methods for LLMs (like Safe RLHF) require training three separate large models (reward model, cost model, policy), incurring prohibitive memory costs.
Why it matters:
- Training three LLM-sized models simultaneously is memory-intensive and computationally expensive, limiting accessibility for researchers with limited hardware
- Alternative methods either require prior knowledge of the optimal solution (Lagrange multiplier) or suffer from inefficient learning, leading to poor safety-helpfulness trade-offs
Concrete Example:
Safe RLHF trains a reward model, a cost model, and a policy model. PD-DPO eliminates the explicit cost model by using a rearranged DPO objective, needing only a reward-aligned model and the final policy.
Key Novelty
Primal-Dual DPO (PD-DPO)
- Uses a pre-trained reward-aligned DPO model to implicitly provide reward information, avoiding the need for a separate explicit reward model during the safety tuning phase
- Formulates a rearranged Lagrangian DPO objective that directly optimizes the policy using cost preference data, conditioned on the reward information from the first model
- Updates the Lagrange multiplier (balancing safety vs. reward) via projected subgradient descent using cost estimates from the current policy
Architecture
The PD-DPO algorithm flow comprising two main phases: Reward Learning and Primal-Dual Updates.
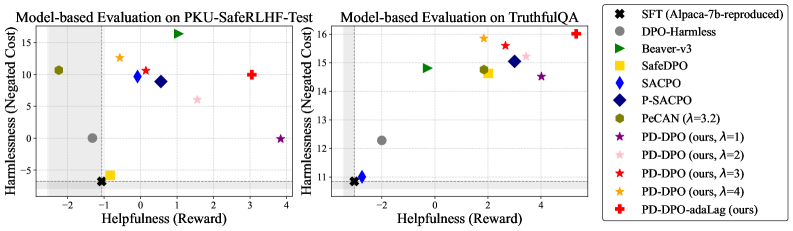
Evaluation Highlights
- Achieves higher reward (helpfulness) while maintaining lower cost (safety) than Safe RLHF and C-DPO baselines on PKU-SafeRLHF dataset
- Reduces memory footprint by ~33% compared to Safe RLHF (requiring 2 models instead of 3)
- Provides rigorous theoretical guarantees for suboptimality and constraint violation, unlike most heuristic safety alignment methods
Breakthrough Assessment
8/10
Strong theoretical grounding with provable convergence coupled with a practical reduction in memory requirements. Sets a new state-of-the-art for efficient constrained alignment.