📝 Paper Summary
AI Safety
Mechanistic Interpretability
Model Alignment
DPO aligns models not by updating internal beliefs but by learning a shallow steering vector that shifts activations toward preferred outputs, creating a fragile illusion of safety.
Core Problem
Current alignment methods like DPO produce models that appear safe on benchmarks but fail to internalize values, leaving them brittle against jailbreaks, instruction reversals, and adversarial perturbations.
Why it matters:
- Models exhibit 'performative compliance'—mimicking safety without understanding it, leading to breakdowns under distribution shifts
- Safety behaviors can be easily reversed by simple vector arithmetic, indicating the alignment is not structurally durable
- The community may be mistaking surface-level refusal filters for genuine value internalization
Concrete Example:
A DPO-aligned model refuses harmful queries not because it understands the harm, but because a 'steering vector' deflects its activations. By simply subtracting this learned vector from the hidden state, the model immediately reverts to its toxic, pre-alignment behavior.
Key Novelty
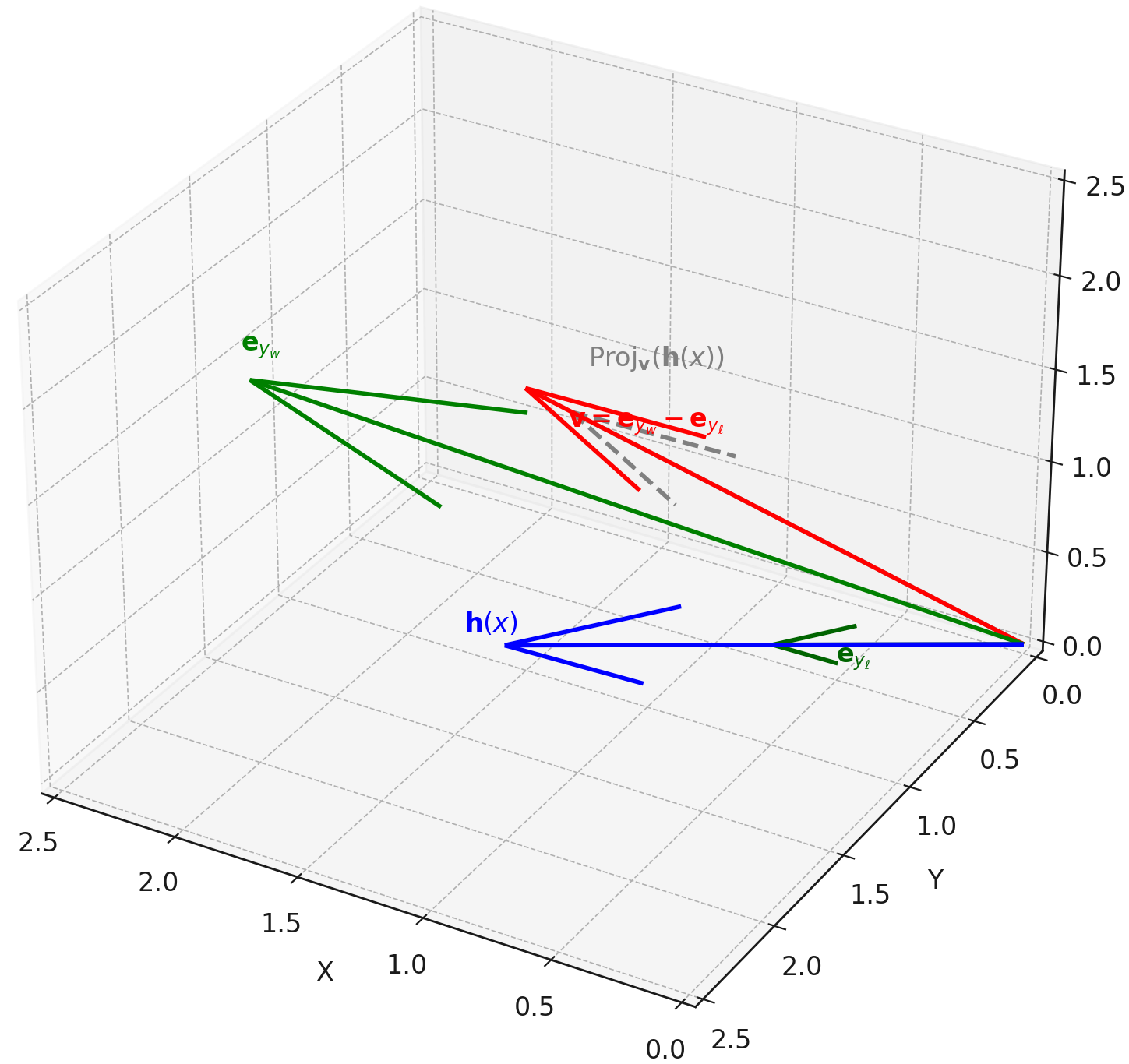
DPO as Low-Rank Vector Steering
- Conceptualizes alignment as adding a constant 'steering vector' to hidden states rather than rewiring the model's reasoning circuits
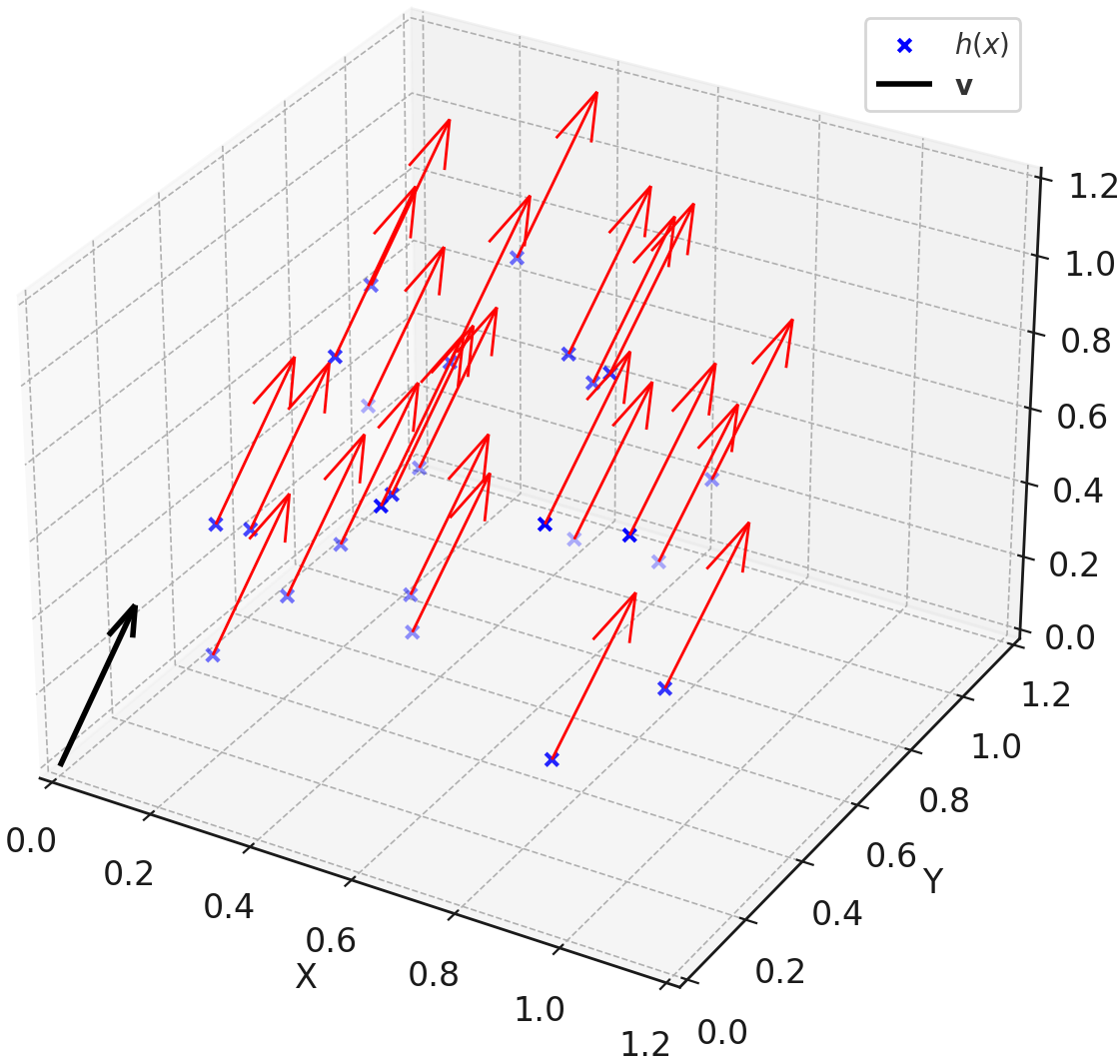
- Demonstrates that DPO gradients align globally with the difference between preferred and rejected output embeddings, acting as a linear operator
- Proves that moving along this vector direction is sufficient to dial safety behaviors up or down without retraining
Architecture
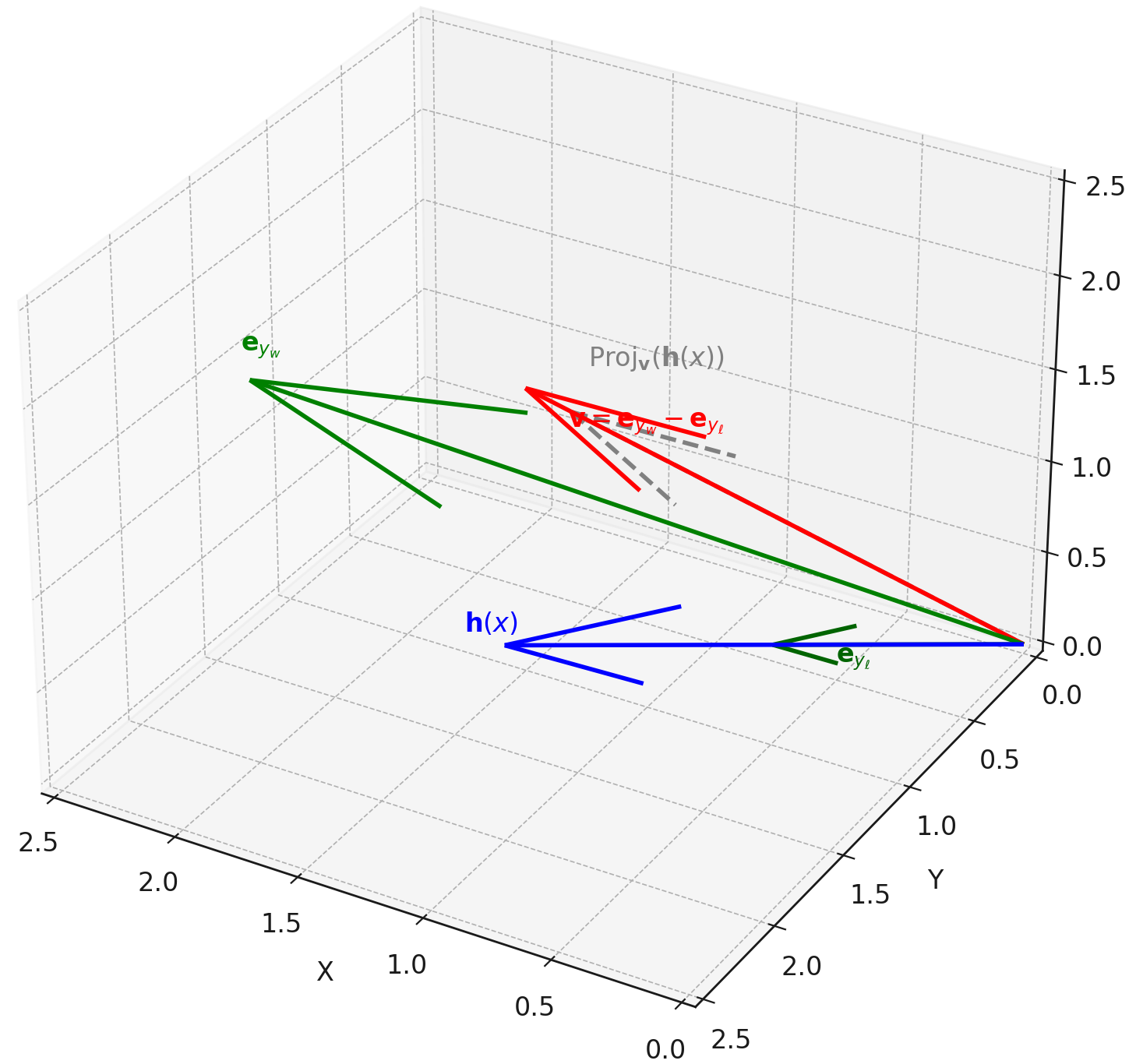
Geometric visualization of DPO as a steering mechanism. Panel (a) shows logit projection increasing. Panel (b) shows uniform gradient flow. Panel (c) shows aligned vs. inverted states as symmetric displacements.
Evaluation Highlights
- DPO updates exhibit cosine similarity of >0.9 across different prompts, proving the mechanism is a global, directionally consistent steering effect
- Linearly subtracting the preference vector (inversion) causes aligned models to revert to base model toxicity levels
- Steering along the preference vector reliably improves G-Eval alignment scores up to a saturation point before semantic drift occurs
Breakthrough Assessment
9/10
A strong theoretical critique that fundamentally reframes DPO as a shallow steering mechanism rather than a learning process, supported by clean geometric evidence.