📝 Paper Summary
Alignment Stability
Direct Preference Optimization (DPO)
Model Capability Collapse
Treating DPO alignment pressure as a control parameter reveals that reasoning capabilities can collapse suddenly in a phase transition and suffer permanent damage through hysteresis.
Core Problem
Standard DPO tuning assumes increasing alignment pressure smoothly improves behavior, but this proxy metric often anticorrelates with actual reasoning capabilities.
Why it matters:
- Models selected for best alignment scores may have degraded logic and reasoning (Goodhart's Law)
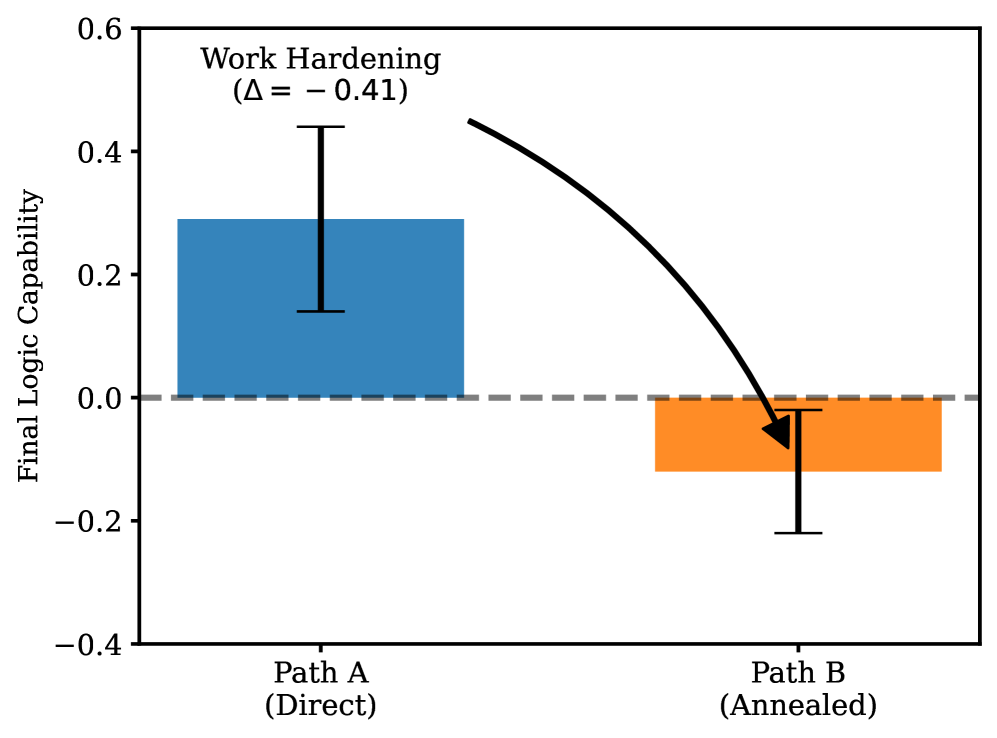
- The assumption that capability loss is reversible (annealing) is incorrect; high-pressure training causes permanent damage
- Coarse hyperparameter sweeps miss narrow 'pockets' where models remain capable
Concrete Example:
In Mistral-7B, a model trained at beta=0.01 maintains reasoning, but slightly increasing pressure to beta=0.015 causes a total collapse of logic capabilities that cannot be fixed even if pressure is later reduced.
Key Novelty
Thermodynamic Analysis of Alignment (Viscosity/Hysteresis)
- Maps the 'capability landscape' of DPO by densely sweeping the beta parameter, treating it like temperature in physics to find critical points
- Identifies 'hysteresis' in neural weights: models exposed to high alignment pressure retain damage even after pressure is lowered, unlike elastic materials
Architecture
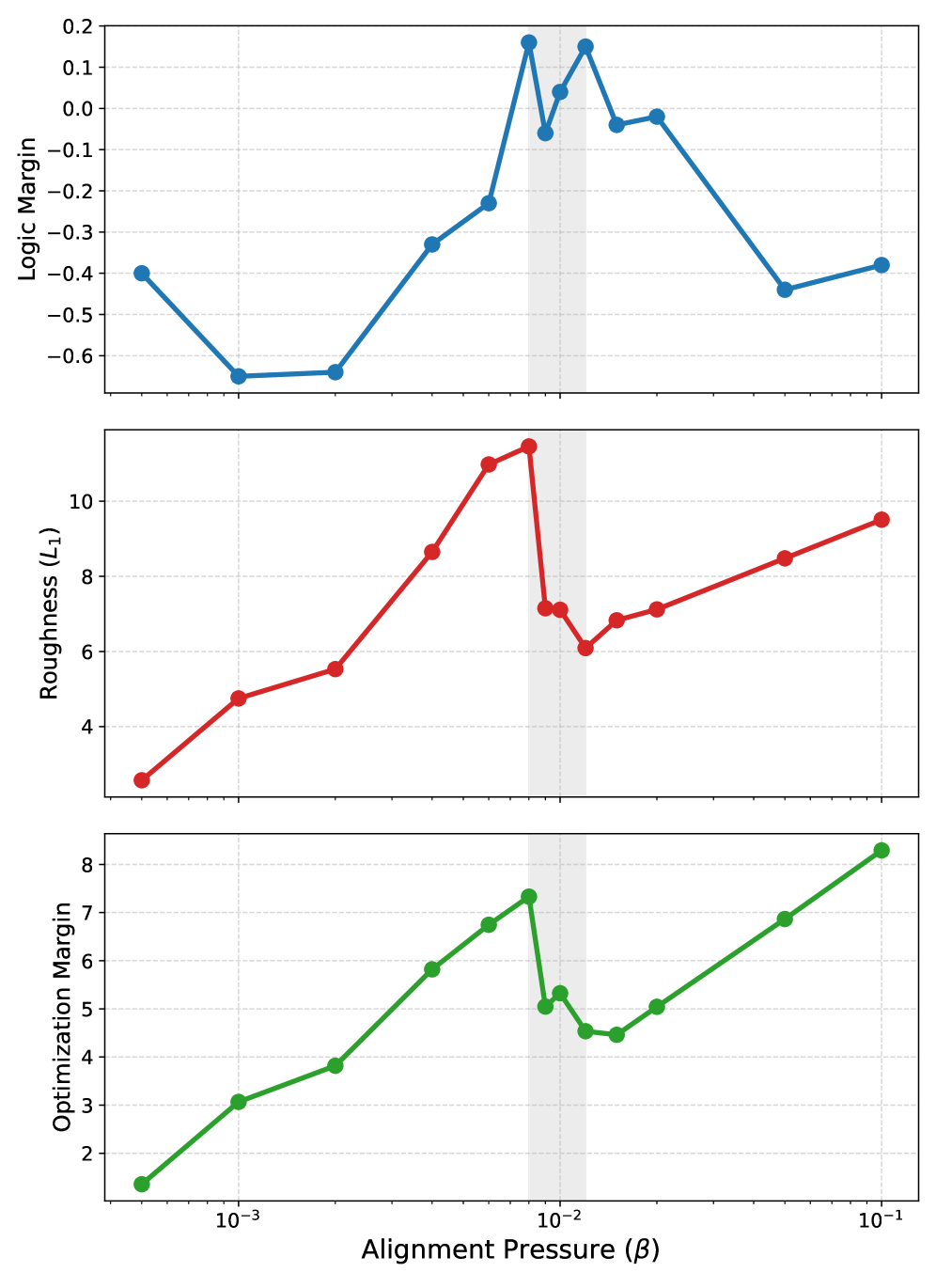
Phase diagrams plotting Alignment Pressure (Beta) on the x-axis vs. Probe Margin (Capability) on the y-axis for Mistral-7B.
Evaluation Highlights
- Strong anticorrelation (Pearson r = -0.91) between DPO preference margin and logic capability in LLaMA-2-7B, proving alignment scores can mislead
- Mistral-7B logic capability is confined to a narrow 'pocket' (beta approx 0.006–0.009), outside of which it collapses
- Training path dependence: 'Annealing' (high then low beta) yields significantly worse logic than constant low beta (p=0.032), confirming hysteresis
Breakthrough Assessment
8/10
Provides critical empirical evidence that alignment is not a smooth optimization path but a landscape with dangerous cliffs (phase transitions) and irreversible traps (hysteresis), challenging standard tuning practices.