📝 Paper Summary
LLM Alignment
Direct Preference Optimization (DPO)
β-DPO improves model alignment by dynamically adjusting the DPO trade-off parameter at the batch level based on data quality and filtering out noisy outliers.
Core Problem
The standard Direct Preference Optimization (DPO) method uses a fixed hyperparameter β, which fails to adapt to varying data qualities (gaps between chosen/rejected responses) and is sensitive to outliers.
Why it matters:
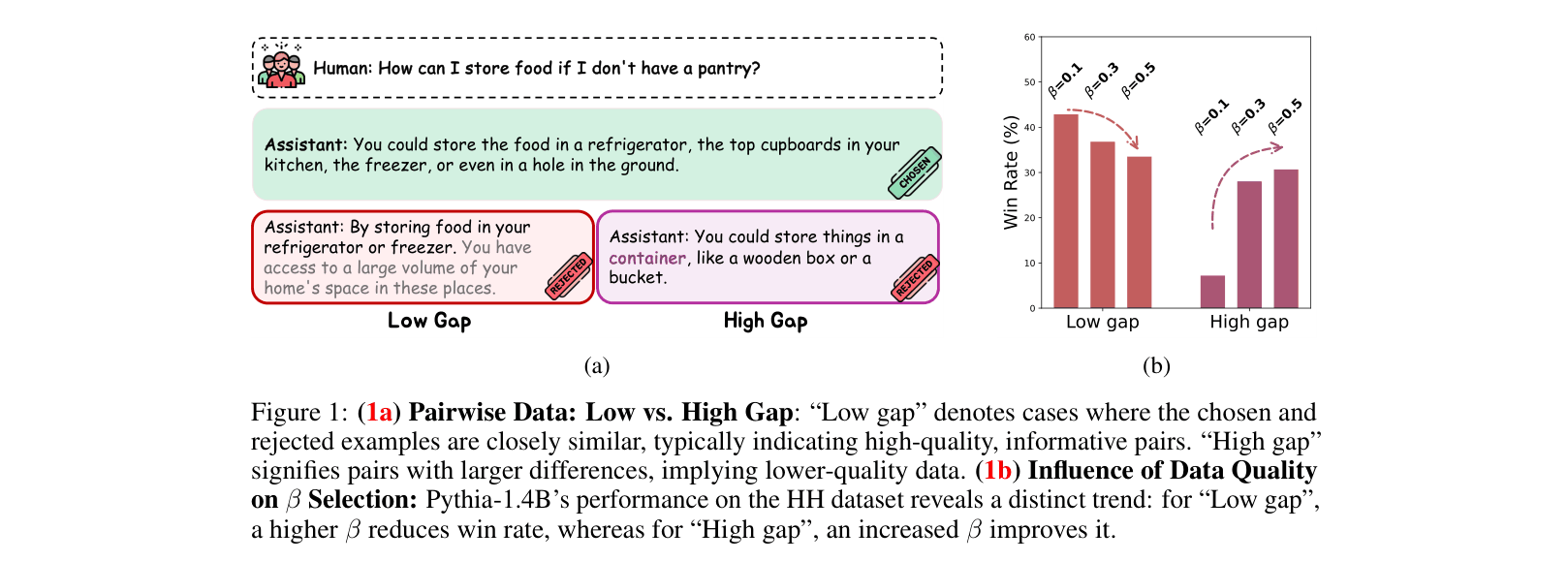
- Using a fixed β leads to suboptimal performance: informative 'low gap' pairs need aggressive updates (low β), while easy 'high gap' pairs need conservative updates (high β) to prevent overfitting.
- Real-world preference datasets contain mixed-quality data and outliers; a static parameter treats informative examples and noise identically, degrading alignment stability.
- Tuning β is computationally expensive and manual, often requiring different values for different datasets or model sizes.
Concrete Example:
In the Anthropic HH dataset, some pairs have a 'low gap' (both responses are similar/high quality), while others have a 'high gap' (one response is clearly terrible). A static β=0.1 might be too conservative for the hard pairs but too aggressive for the easy/noisy ones, leading to lower win rates.
Key Novelty
Dynamic β Calibration and β-Guided Data Filtering
- Calculates the 'reward discrepancy' (difference in scores between chosen and rejected answers) for each batch during training to measure data quality.
- Dynamically adjusts β per batch: increases β (conservative) for large discrepancies to avoid overfitting to easy/noisy data, and decreases β (aggressive) for small discrepancies to learn from hard examples.
- Filters out data points that statistically deviate too far from the average reward discrepancy (outliers) using a moving average technique, ensuring stable updates.
Architecture
Pseudocode of the β-DPO training process.
Evaluation Highlights
- Achieves 57.07% win rate on Anthropic HH with Pythia-2.8B, outperforming vanilla DPO (51.51%) by a substantial margin.
- Outperforms SimPO (Simple Preference Optimization) on AlpacaEval 2 using Llama3-8B-Instruct, raising the win rate from 38.97% to 40.18%.
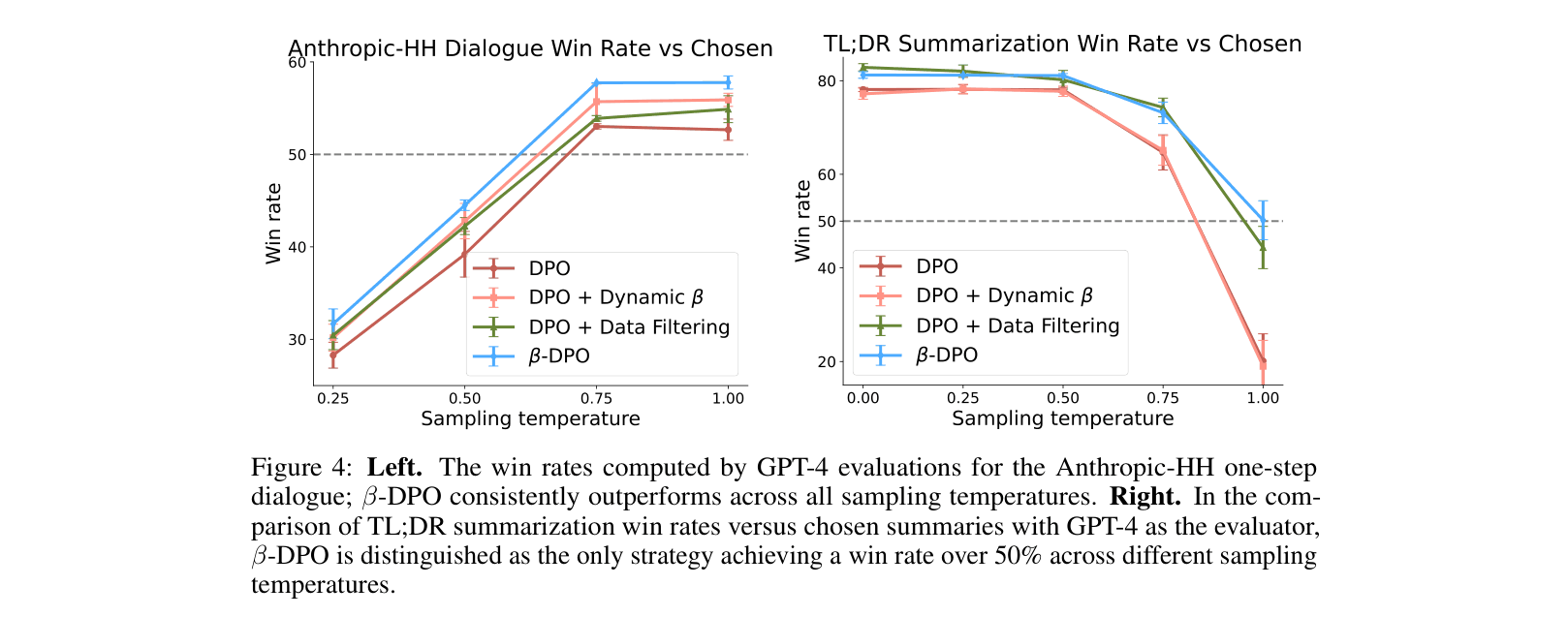
- Demonstrates robustness to sampling temperature variations on the TL;DR summarization task, maintaining >50% win rate while standard DPO drops to ~25% at higher temperatures.
Breakthrough Assessment
7/10
Offers a simple, plug-and-play improvement to DPO that addresses a known sensitivity issue (β tuning) with consistent empirical gains across multiple models and benchmarks.