📝 Paper Summary
LLM Alignment
Direct Preference Optimization (DPO)
Curri-DPO aligns LLMs by deriving multiple preference pairs from single prompts and training on them sequentially from easiest (large quality gap) to hardest (small quality gap).
Core Problem
Standard DPO wastes data by using only a single chosen/rejected pair per prompt, ignoring the richer signal available in multiple ranked responses.
Why it matters:
- Existing methods discard valid preference signals (e.g., 2nd best vs. worst) which could act as data augmentation
- Learning contrastive signals is inefficient when models are immediately exposed to hard-to-distinguish pairs (similar quality) without a curriculum
- High-quality response curation is expensive; maximizing utility from existing ranked responses improves efficiency
Concrete Example:
For a prompt with responses ranked R1 > R2 > R3 > R4, standard DPO only uses (R1, R4). It ignores that distinguishing R1 from R4 is 'easy', while distinguishing R1 from R2 (both good) is 'hard' but crucial for fine-grained alignment.
Key Novelty
Curriculum-based Direct Preference Optimization (Curri-DPO)
- Decomposes a ranked list of responses (R1>R2>R3>R4) into multiple pairwise comparisons (e.g., R1 vs R4, R1 vs R3, R1 vs R2)
- Orders training data by difficulty: starts with 'easy' pairs (large quality gap, R1 vs R4) and progresses to 'hard' pairs (small quality gap, R1 vs R2)
- Iteratively updates the reference model: the model from iteration 'i' becomes the reference for iteration 'i+1', allowing progressive alignment
Architecture
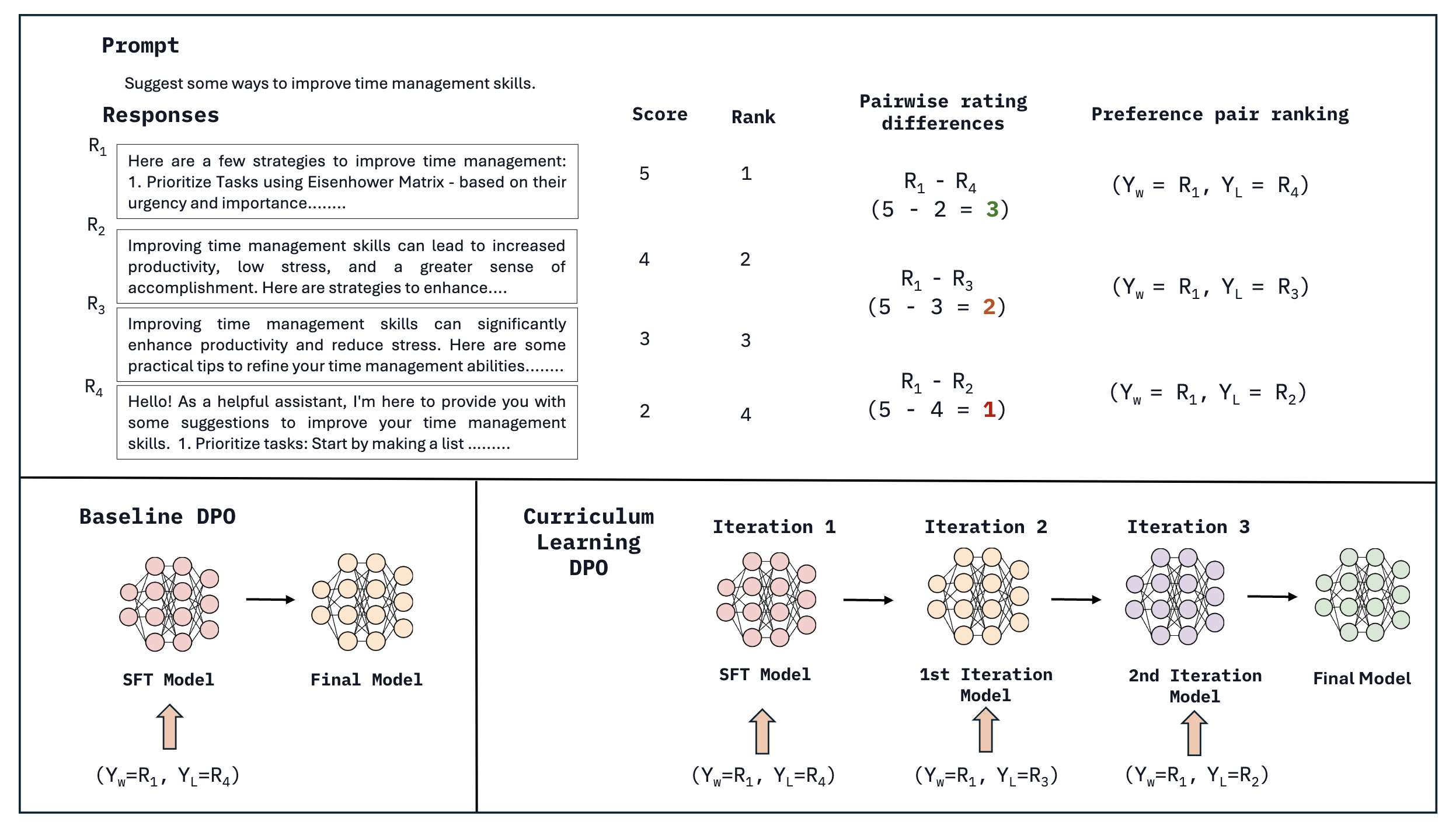
Illustration of the Curriculum DPO process showing how multiple preference pairs are created from ranked responses and ordered by difficulty.
Evaluation Highlights
- 7.43 score on MT-Bench with Zephyr-7B, outperforming the majority of existing LLMs with similar parameter sizes
- Achieves 90.7% win rate on Vicuna bench (Zephyr-7B), showing strong alignment performance
- Notable gains of up to 7.5% on Vicuna, WizardLM, and UltraFeedback test sets compared to standard single-pair DPO
Breakthrough Assessment
7/10
A simple yet effective extension to DPO that leverages curriculum learning and data augmentation from ranked lists, showing consistent gains over standard DPO without changing the underlying loss function.