📝 Paper Summary
Mathematical Reasoning
LLM Alignment
Step-Controlled DPO improves mathematical reasoning by generating synthetic negative samples that start deviating from a correct solution at a specific step, enabling precise stepwise error supervision.
Core Problem
Naive DPO supervises models based only on the final answer, failing to capture the intricacies of multi-step reasoning where errors can occur at subtle intermediate steps.
Why it matters:
- Mathematical problems often have a single correct final answer but diverse reasoning paths, making final-answer supervision too coarse.
- Existing process supervision methods require expensive human annotation to label individual steps.
- Models need to learn exactly *where* they went wrong in a reasoning chain to improve reliability, rather than just being penalized for the final result.
Concrete Example:
A model might solve a math problem correctly up to step 3, then make a calculation error in step 4 that leads to a wrong answer. Naive DPO penalizes the entire sequence, potentially discouraging the correct steps (1-3), whereas the proposed method specifically targets the divergence at step 4.
Key Novelty
Step-Controlled DPO (SCDPO)
- Takes a correct 'preferred' solution and forces the model to generate a 'dispreferred' branch starting from a random intermediate step by increasing softmax temperature.
- Constructs DPO pairs where the prompt includes the question plus all correct steps *before* the branch point.
- Apply DPO loss only to the steps *after* the branching point, teaching the model to prefer the correct continuation over the erroneous one given the same valid history.
Architecture
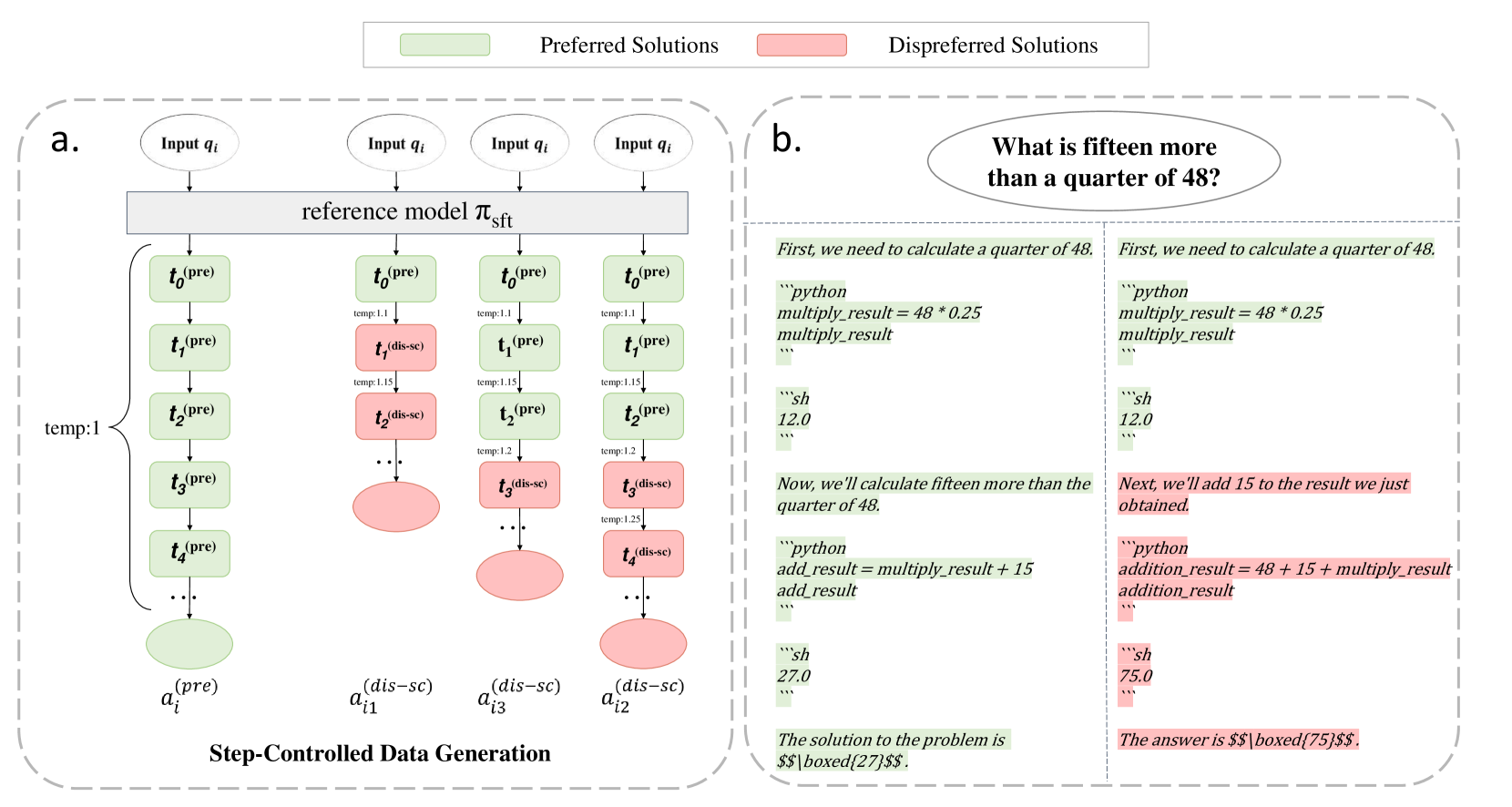
The data generation and training pipeline for Step-Controlled DPO.
Evaluation Highlights
- Finetuned InternLM2-20B using SCDPO achieves 88.5% on GSM8K and 58.1% on MATH, rivaling other open-source models.
- Improves GSM8K accuracy by +3.8% and MATH by +2.7% over a strong SFT baseline when applied to a Mistral-7B model.
- Consistently outperforms naive DPO across three different base models (Mistral-7B, MetaMath-Mistral-7B, MathCoder-Mistral-7B).
Breakthrough Assessment
8/10
Simple yet highly effective method for automatic stepwise supervision without human labeling. Significant performance gains on standard benchmarks (GSM8K/MATH) establish it as a strong technique for reasoning alignment.
