📝 Paper Summary
LLM Alignment
Preference Optimization
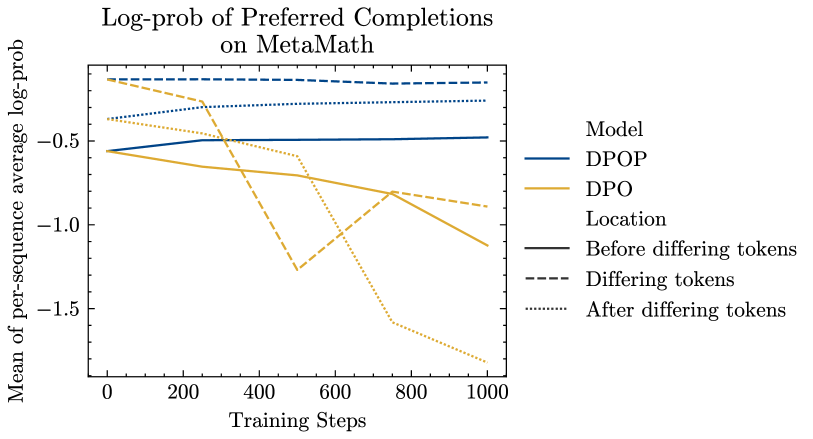
The paper identifies that Direct Preference Optimization (DPO) incorrectly reduces the probability of preferred completions when edit distances are low, and proposes DPO-Positive (DPOP) to penalize this reduction, achieving state-of-the-art open-source performance.
Core Problem
Standard DPO loss can effectively minimize its objective by lowering the likelihood of the preferred completion, as long as the dispreferred completion is lowered even more, leading to model degradation.
Why it matters:
- This phenomenon causes the model to 'forget' or reduce the probability of generating correct, high-quality responses even if they are preferred.
- The issue is catastrophic in datasets where preferred and dispreferred pairs have low edit distance (e.g., math or reasoning), which are critical for advanced LLM capabilities.
Concrete Example:
Consider a math pair: '2+2=4' (preferred) vs '2+2=5' (dispreferred). These differ by only one token. To maximize the ratio gap, DPO might suppress the probability of the shared prefix '2+2=' or the correct token '4' in the preferred sequence, provided it suppresses '5' in the dispreferred sequence more aggressively.
Key Novelty
DPO-Positive (DPOP)
- Identifies a theoretical failure mode where DPO reduces the log-likelihood of preferred examples to satisfy the relative margin objective.
- Proposes a modified loss function (DPOP) that adds a penalty term specifically to prevent the model from reducing the likelihood of the positive (preferred) completion relative to the reference model.
Architecture
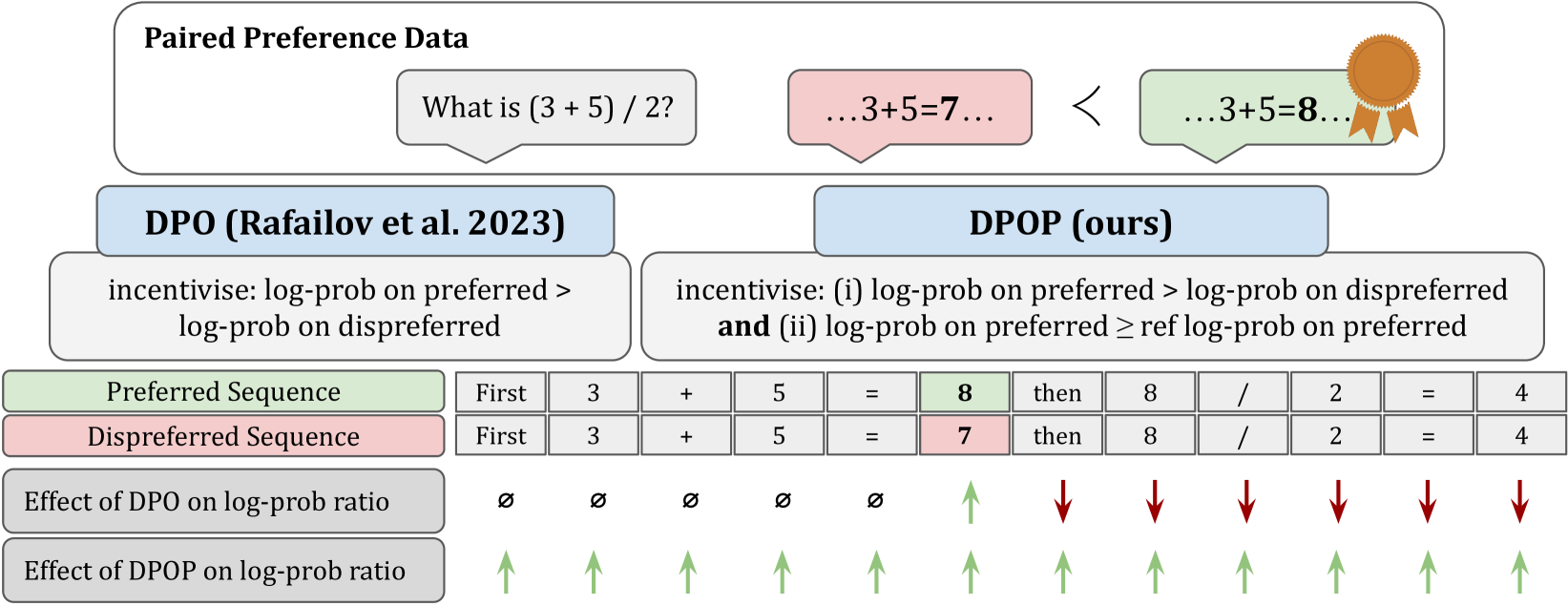
Conceptual illustration of DPO's failure mode on token probabilities.
Evaluation Highlights
- Smaug-72B achieves an average accuracy of 80.48% on the HuggingFace Open LLM Leaderboard, becoming the first open-source LLM to surpass 80%.
- Smaug-72B improves by nearly 2% over the previous second-best open-source model on the HuggingFace Leaderboard.
- DPOP-tuned models outperform standard DPO-tuned models on MT-Bench, a benchmark independent of the fine-tuning data.
Breakthrough Assessment
9/10
Identifies a fundamental theoretical flaw in a widely used method (DPO) and provides a fix that results in the first open-source model to cross the significant 80% threshold on the HF Leaderboard.