📝 Paper Summary
LLM Alignment
Preference Optimization
Self-Play / Self-Alignment
DICE iteratively self-aligns language models by using the implicit reward signal from a DPO-trained model to rank its own outputs, combined with length regularization and experience replay to prevent degradation.
Core Problem
Standard DPO training on a fixed offline dataset is suboptimal compared to online methods, but collecting new human preference labels for iterative training is expensive and slow.
Why it matters:
- Current alignment methods rely heavily on costly human feedback (RLHF) or external reward models, creating a bottleneck for scaling model improvements
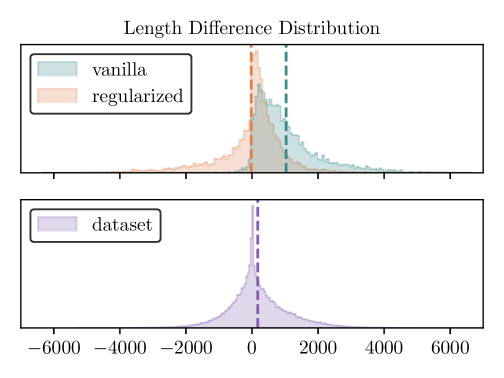
- Iterative self-training often leads to 'length exploitation,' where models learn to generate longer, more verbose responses rather than better ones to game the reward system
- Repeated fine-tuning on model-generated data can cause 'catastrophic forgetting,' where the model loses the original knowledge or safety constraints embedded during initial training
Concrete Example:
A standard DPO model might learn that longer answers are generally preferred. When used to self-label data for a second round, it ranks a verbose, repetitive answer higher than a concise correct one. Retraining on this reinforces verbosity, causing the model to output increasingly bloated text without improving quality.
Key Novelty
Self-alignment with DPO ImpliCit rEwards (DICE)
- Uses the mathematical property that a DPO-trained model inherently contains an 'implicit reward' function, effectively allowing the model to act as its own judge without a separate reward model
- Applies 'length-regularized reward shaping' during the data selection phase to create a length-unbiased preference dataset, rather than modifying the training loss
- incorporates 'experience replay' by mixing high-quality offline human data with the new self-generated data to stabilize training and prevent forgetting
Architecture
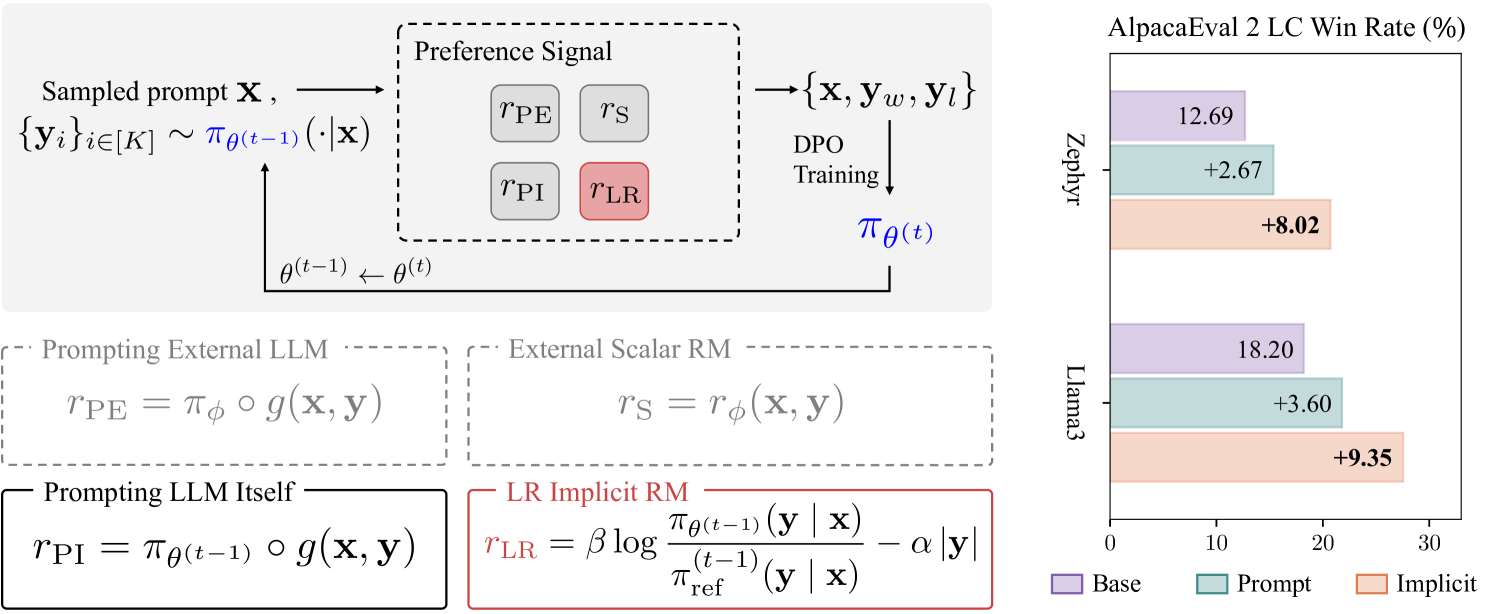
The iterative self-alignment workflow of DICE.
Evaluation Highlights
- +8.02% length-controlled (LC) win rate improvement on AlpacaEval 2 for the Zephyr-based model compared to the DPO baseline
- +9.35% LC win rate improvement on AlpacaEval 2 for the Llama3-based model compared to the DPO baseline
- Outperforms iterative DPO baselines (like Self-Rewarding LM) that rely on LLM-as-a-judge prompting rather than implicit rewards
Breakthrough Assessment
7/10
Strong empirical results on standard benchmarks (AlpacaEval 2) showing that implicit rewards are sufficient for self-improvement without external judges. The combination of implicit rewards with length regularization addresses a critical failure mode of self-play.