📝 Paper Summary
LLM Alignment
Direct Preference Optimization (DPO)
Continual Learning
OFS-DPO simulates biological intraspecific competition using fast and slow LoRA modules to improve online preference alignment and mitigate catastrophic forgetting in cross-domain scenarios.
Core Problem
Standard DPO is designed for offline training and fails to adapt to online data streams, while direct continual training on cross-domain preferences causes catastrophic forgetting of previous tasks.
Why it matters:
- The cycle of forgetting and relearning in standard DPO increases computational costs and data collection requirements
- Existing online alignment methods often require expensive reward models (like PPO) or lack flexible modularity to retain memory efficiently
- Directly applying DPO to streaming data leads to performance degradation on earlier domains, limiting its utility for long-term deployment
Concrete Example:
When a model aligned on a summarization task is subsequently trained on a dialogue task using standard DPO, it forgets the summarization preferences, degrading performance on the original task.
Key Novelty
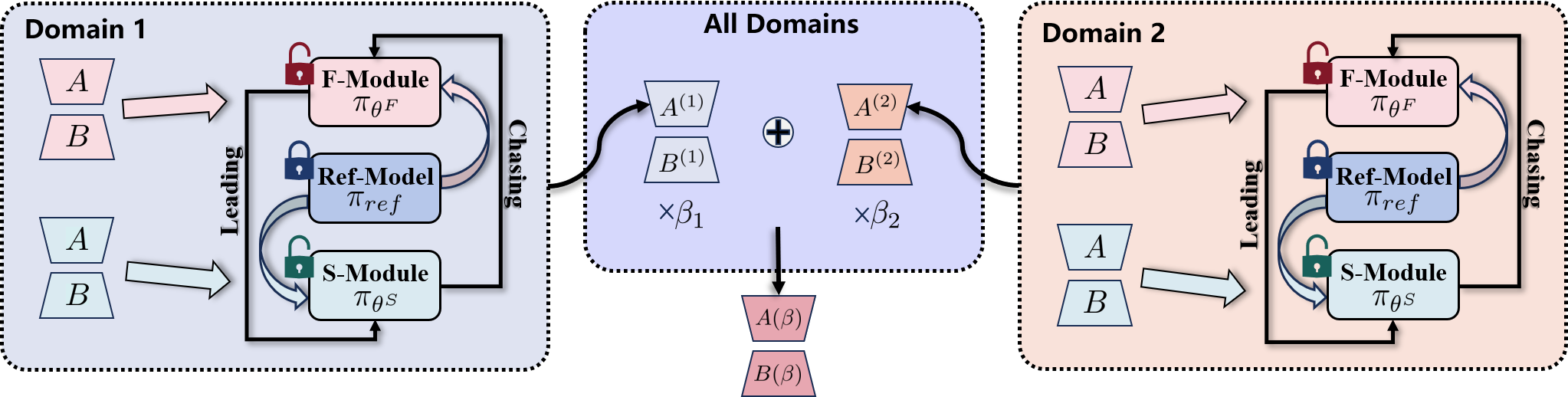
Online Fast-Slow Chasing DPO (OFS-DPO) and Cross-Domain OFS-DPO (COFS-DPO)
- Simulates intraspecific competition by maintaining two LoRA modules (Fast and Slow) that 'chase' each other toward the optimal policy
- Introduces a regularization term minimizing the preference probability gap between modules, ensuring stable gradient updates unlike standard DPO where gradients diminish
- For cross-domain tasks, COFS-DPO linearly combines optimal fast modules from different domains to balance new learning with historical memory preservation
Architecture
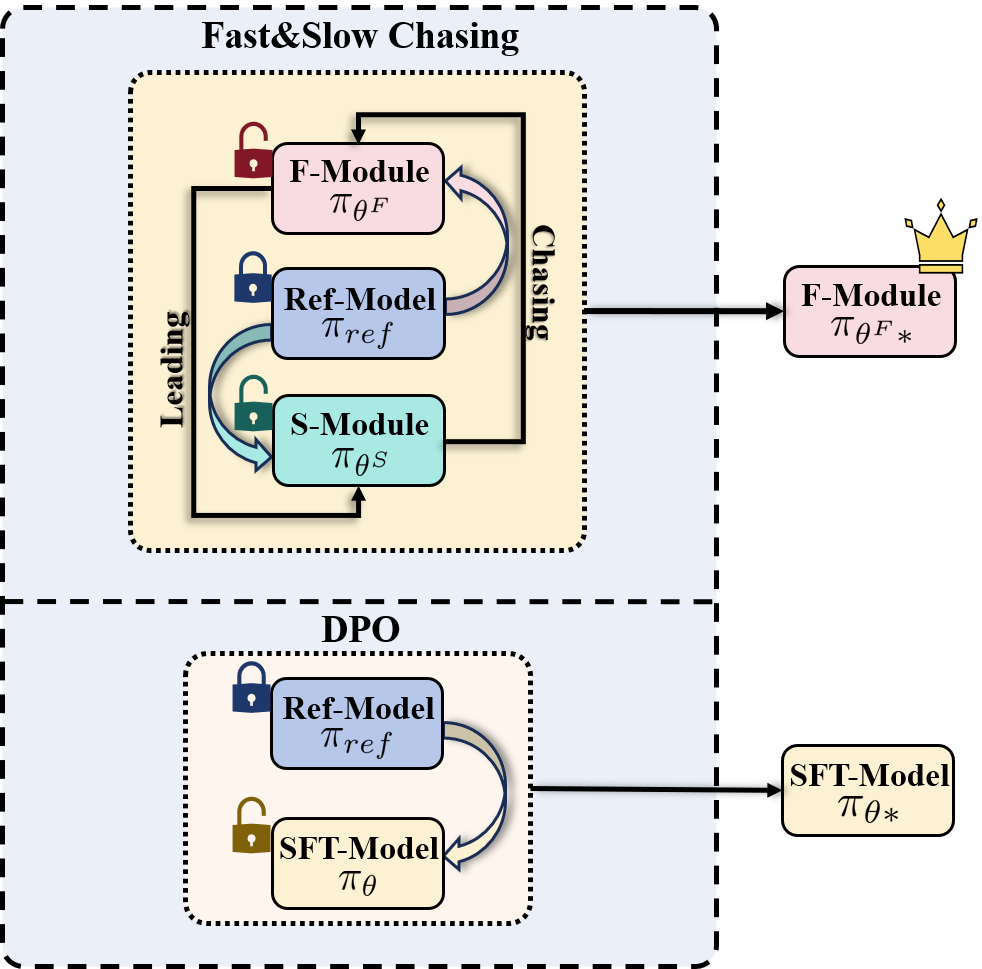
Illustration of the OFS-DPO chasing mechanism vs. Offline Optimal. It shows two modules (Fast and Slow) approximating the offline optimal decision.
Evaluation Highlights
- OFS-DPO outperforms standard DPO in in-domain sentiment generation, summarization, and dialogue tasks (e.g., lower perplexity and better alignment)
- COFS-DPO achieves comparable performance to theoretically optimal parameters across combined domains while retaining domain-specific memory
- Theoretical analysis proves OFS-DPO achieves a lower empirical regret bound and more sustained gradient momentum compared to standard DPO
Breakthrough Assessment
7/10
Novel application of biological competition theory to DPO with strong theoretical grounding (regret bounds). Effectively addresses the specific niche of online/continual DPO without reward models.