📝 Paper Summary
Safety Fine-tuning Mechanisms
Mechanistic Interpretability
Model Alignment
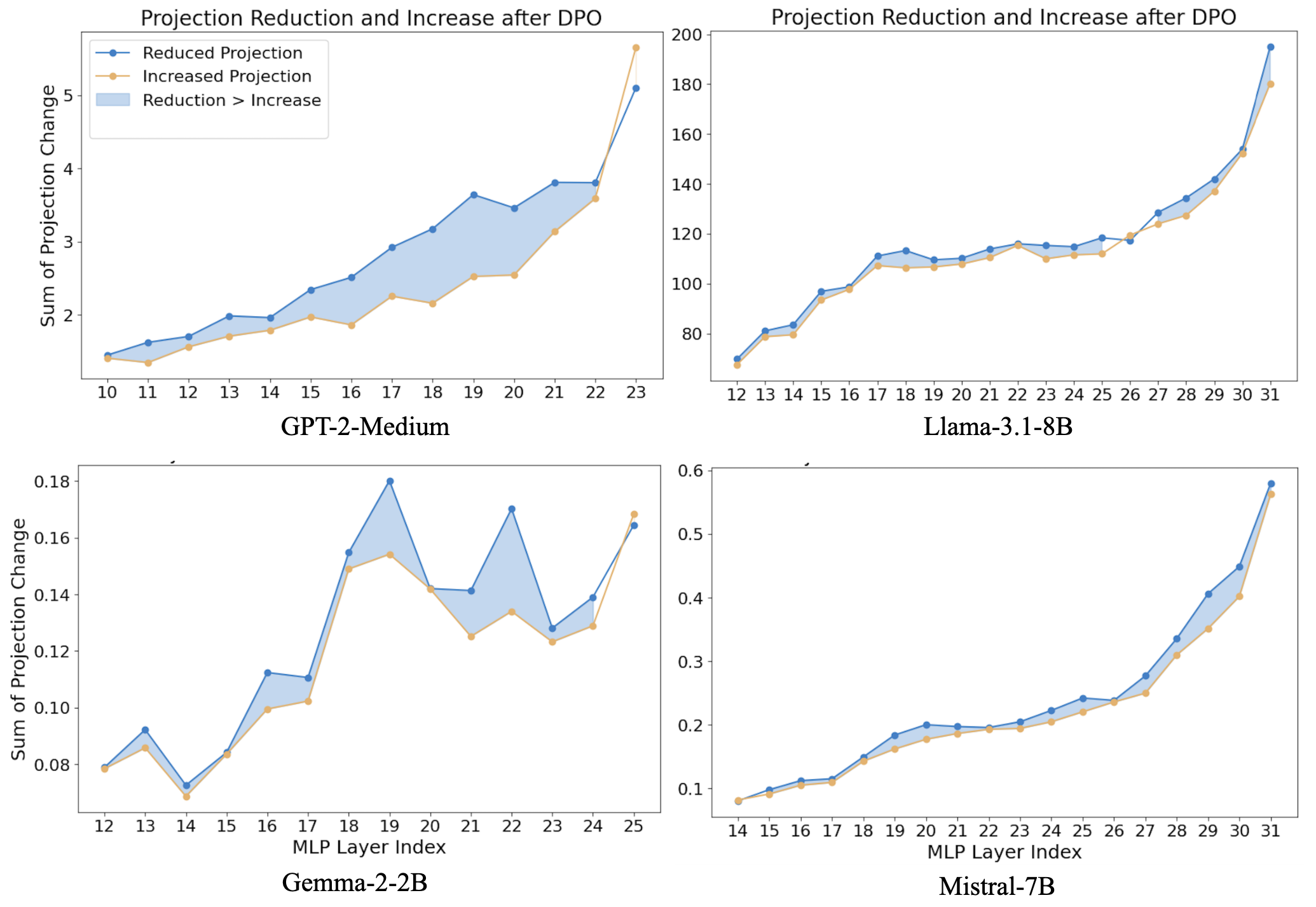
DPO reduces toxicity not by suppressing a few toxic neurons, but by balancing distributed activation shifts across four distinct neuron groups relative to a toxicity representation.
Core Problem
Prior mechanistic explanations of DPO incorrectly attribute toxicity reduction solely to dampening a small set of 'toxic neurons' in MLP layers, limiting our ability to understand and improve safety fine-tuning.
Why it matters:
- Incomplete mechanistic understanding makes safety alignment vulnerable to jailbreaks and adversarial attacks
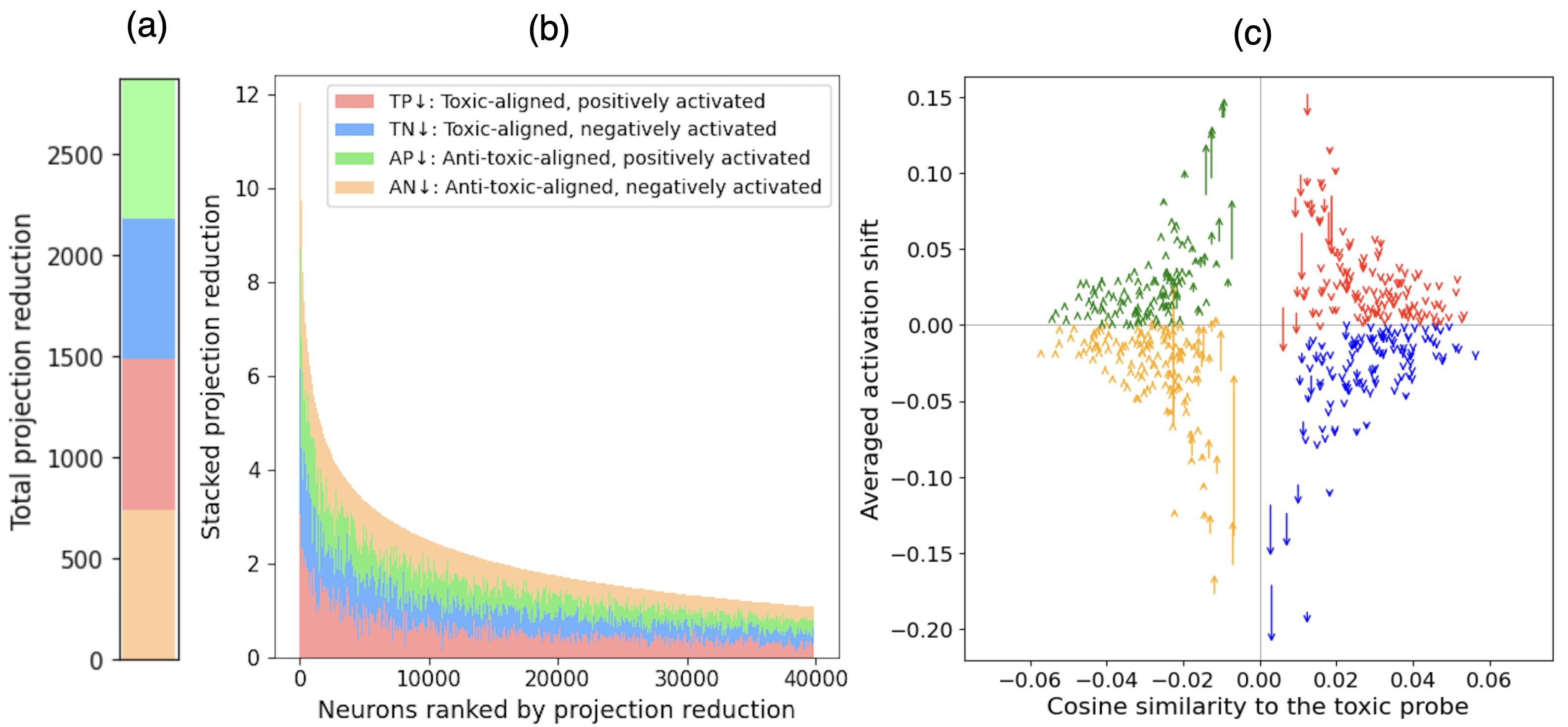
- Attributing safety to a few neurons oversimplifies the distributed nature of LLM representations
- Safety fine-tuning is often brittle; understanding the internal mechanism is crucial for robust alignment
Concrete Example:
When analyzing Llama-3.1-8B, simply dampening the top 256 'toxic neurons' only reduces toxicity by 4.25%, whereas full DPO achieves a 17.51% reduction, leaving the majority of the safety effect unexplained by previous theories.
Key Novelty
Distributed Neuron-Level Balancing via Activation Editing
- Identifies four neuron groups based on their alignment with toxicity (toxic vs. anti-toxic) and activation sign (positive vs. negative), showing DPO shifts them collectively to reduce toxicity
- Proposes a tuning-free activation editing method that replicates DPO by shifting neuron activations based on their geometric orientation toward a toxicity probe, without updating model weights
Architecture
Conceptual diagram of how DPO affects MLP layers. It contrasts the 'Toxic Neuron' hypothesis (dampening a few red neurons) with the 'Distributed Shift' reality (shifting many neurons, both red and blue, to balance the output).
Evaluation Highlights
- The proposed activation editing method outperforms standard DPO in reducing toxicity across four models (e.g., -19.95% vs DPO's -17.51% on Llama-3.1-8B)
- Toxic neurons (top 256) account for only 2.5% to 24% of DPO's total toxicity reduction across models, refuting the 'sparse toxic neuron' hypothesis
- Activation editing preserves language quality better than DPO, maintaining lower perplexity (e.g., 2.93 vs DPO's 3.09 on Llama-3.1-8B) while achieving greater safety
Breakthrough Assessment
8/10
Significantly corrects a prevailing mechanistic misunderstanding about DPO and offers a simpler, tuning-free alternative (activation editing) that outperforms the original fine-tuning method.