📝 Paper Summary
Robust Preference Alignment
Reward Design for Public Health
DPO-PRO improves the robustness of language model fine-tuning by incorporating uncertainty in human preference labels into the Direct Preference Optimization loss, specifically for designing reward functions in public health resource allocation.
Core Problem
In high-stakes domains like public health, human preference data for reward functions is inherently noisy and ambiguous, leading standard alignment methods like DPO to overfit or reward-hack.
Why it matters:
- Public health objectives (e.g., 'prioritize vulnerable mothers') are subjective and ambiguous, making consistent annotation difficult
- Assessing reward functions requires complex reasoning about long-term policy outcomes, increasing label noise compared to standard text tasks
- Standard DPO assumes reliable preference labels; noise can lead to misaligned policies that waste limited resources in real-world deployments
Concrete Example:
When an annotator is unsure whether Reward Function A (prioritizing age) or Reward Function B (prioritizing income) better meets a vague goal like 'help the most vulnerable', standard DPO forces the model to fully commit to the noisy label. DPO-PRO detects this uncertainty (preference probability near 0.5) and reduces the gradient update, preventing the model from learning confidently from ambiguous signals.
Key Novelty
Distributionally Robust DPO with Preference Uncertainty (DPO-PRO)
- Models the preference label not as a fixed ground truth but as a distribution with uncertainty, applying Distributionally Robust Optimization (DRO) to hedge against worst-case deviations
- Unlike prior methods that robustify the entire joint distribution (prompts + responses), DPO-PRO focuses solely on the preference probability, resulting in a lightweight, closed-form analytic solution
- Can be interpreted as a regularized DPO loss that dynamically penalizes the model for being overconfident when the underlying preference signal is weak or ambiguous
Architecture
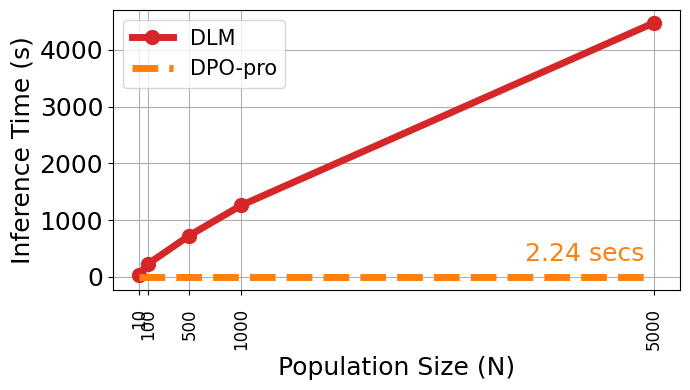
Comparison of inference-time costs and performance between DPO-PRO and self-reflection baselines
Evaluation Highlights
- Achieves comparable performance to DLM (a self-reflection baseline) on the ARMMAN maternal health task while reducing inference cost significantly (no iterative simulation needed)
- Outperforms vanilla DPO and prior DRO baselines (Dr.DPO) in robustness to noisy preference labels on both UltraFeedback and public health simulation tasks
- Demonstrates consistent improvement in alignment accuracy across various noise levels in preference annotations
Breakthrough Assessment
7/10
Offers a mathematically elegant, computationally negligible fix for a critical practical problem (noisy preferences) with strong application to high-stakes public health, though the core algorithmic innovation is a specific application of DRO.