📝 Paper Summary
Post-training for Reasoning
Iterative Direct Preference Optimization (DPO)
Iterative DPO, using verifiable correctness rewards and online data generation, matches the reasoning performance of complex reinforcement learning methods while requiring significantly less computational power.
Core Problem
Reinforcement learning (RL) methods like PPO are effective for enhancing reasoning but are computationally expensive and unstable to train, while offline methods like DPO often lack the exploration needed for self-improvement.
Why it matters:
- High-performance reasoning models (like O1) typically rely on massive RL resources (e.g., SimpleRL requires 32 H100 GPUs), making reproduction difficult for academic labs.
- Current offline methods (standard DPO) struggle to improve beyond the base model's capacity without iterative online exploration.
- There is a need for a scalable, low-resource alternative to RL that still achieves 'Type 2' reasoning capabilities (self-correction, verification).
Concrete Example:
Training the SimpleRL model requires 1.5 days on 32 H100 GPUs. In contrast, the proposed DPO-VP approach achieves comparable accuracy on hard math benchmarks using only a single 80GB GPU for the training steps.
Key Novelty
Iterative DPO with Verifiable Pairs (DPO-VP)
- Instead of using a fixed dataset, the model generates its own data iteratively, labeling responses as positive/negative based on final answer correctness (verifiable rewards).
- Updates both the Generator and the Reward Model (PRM) in a mutual improvement loop: the Generator creates harder data to retrain the PRM, which in turn filters better data for the Generator.
- Applies annealed sampling (increasing temperature over epochs) to maintain diversity as the model converges.
Architecture
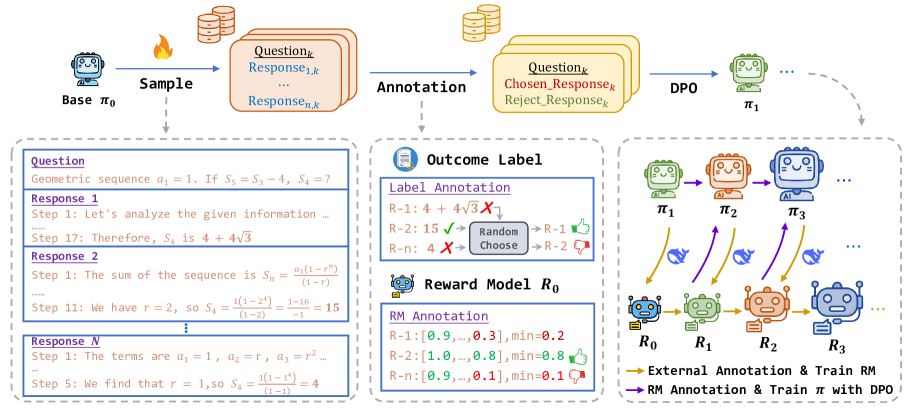
The iterative DPO training framework, showing the cycle of sampling, labeling, and updating both the policy and the reward model.
Evaluation Highlights
- Achieves 48.2% average accuracy across 5 challenging math benchmarks (AIME, AMC, etc.), comparable to RL-based SimpleRL-Zero (48.8%) and PURE-VR (47.7%).
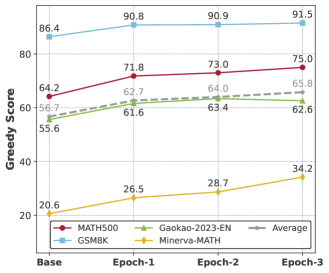
- Single-round DPO with simple outcome supervision boosts Qwen2.5-7B's MATH500 accuracy from 66.8% to 72.8% (+6.0%).
- Reduces computational resources drastically: full iterative training runs on a single 80GB GPU in ~3 days, compared to multi-node clusters for RL baselines.
Breakthrough Assessment
8/10
Significantly lowers the barrier to entry for training reasoning models by matching RL performance with DPO, a much simpler and cheaper objective. Empirical rigor is high.