📝 Paper Summary
LLM Alignment
Direct Preference Optimization (DPO)
Token-level reward modeling
TIS-DPO improves language model alignment by assigning unique importance weights to each token during training, rather than treating entire responses as uniformly good or bad.
Core Problem
Standard DPO (Direct Preference Optimization) treats a whole response as a single unit, ignoring that 'winning' responses often contain poor tokens and 'losing' responses contain good tokens.
Why it matters:
- Uniformly increasing probabilities for all tokens in a winning response reinforces mistakes or low-quality segments within that response.
- The assumption that all tokens in a preferred response are equally good introduces significant noise, reducing optimization efficiency and final model performance.
Concrete Example:
In a summarization task, a 'winning' summary might be preferred overall but still contain a hallucinated fact or a grammatical error. Standard DPO boosts the probability of that error just as much as the correct parts. TIS-DPO would assign a low weight to the error token, preventing the model from learning it.
Key Novelty
Token-level Importance Sampling DPO (TIS-DPO)
- Hypothesizes an 'optimal' dataset where every token in a winning response is equally good. Since real data isn't like this, it uses importance sampling to adjust the training loss.
- Estimates token-level quality (weights) by comparing probabilities from two 'contrastive' models—one biased towards good responses and one towards bad responses.
- Reweights the standard DPO loss per token: high-quality tokens in winners get higher weights; low-quality tokens get lower weights, effectively denoising the signal.
Architecture
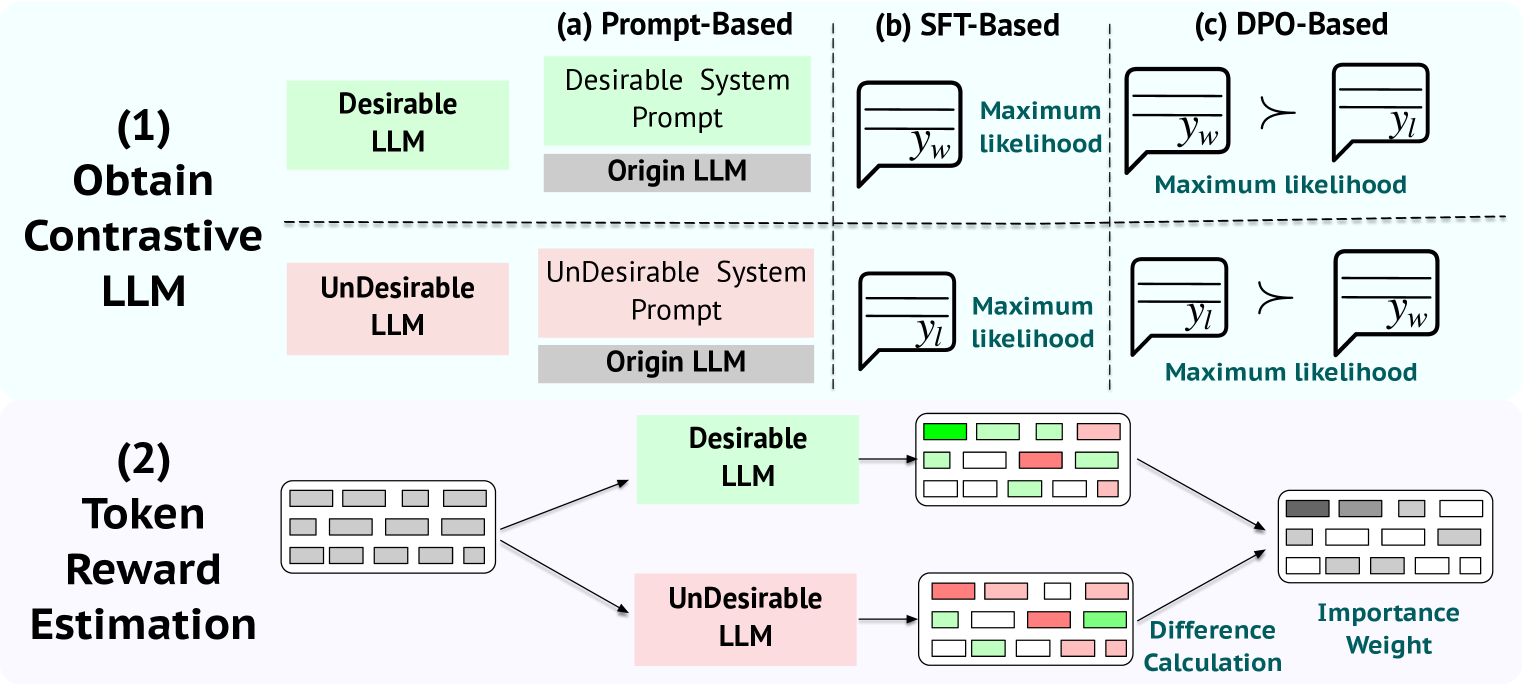
The workflow of TIS-DPO, illustrating the two-step process: (1) Token Weight Estimation using contrastive LLMs, and (2) Weighted DPO Optimization.
Evaluation Highlights
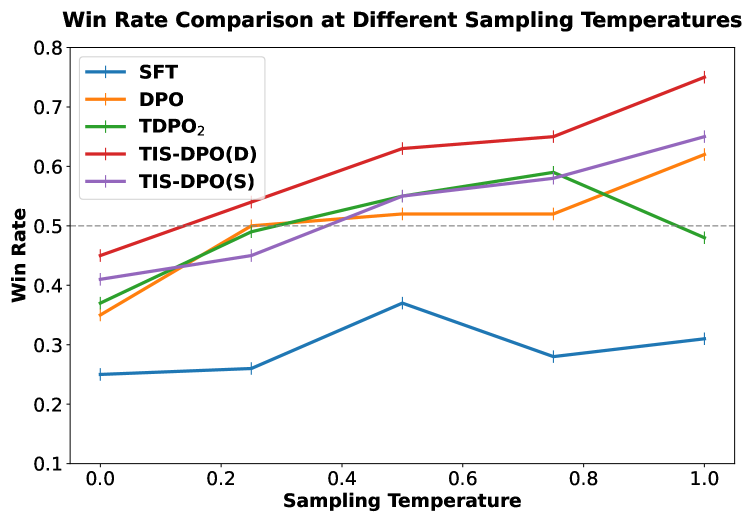
- +3.45% win rate improvement over standard DPO on the Anthropic-HH harmlessness benchmark using Llama-2-7B.
- +2.37% win rate improvement over DPO on the PKU-RLHF helpfulness benchmark.
- Achieves higher reward scores while maintaining lower KL divergence (staying closer to the reference model) compared to baselines like IPO and KTO.
Breakthrough Assessment
7/10
Offers a theoretically grounded improvement to DPO with practical estimation methods. The gains are consistent across tasks, addressing a known granularity issue in preference learning.