📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Inference-time Search
Controlled Text Generation
PPO-MCTS utilizes the typically discarded value model trained during Proximal Policy Optimization to guide Monte-Carlo Tree Search at inference time, improving text alignment without additional training.
Core Problem
Standard PPO deployment discards the value model and relies solely on the policy for decoding, which can lead to suboptimal, misaligned generation even after training.
Why it matters:
- The value model contains critical information about expected future rewards for partial sequences that is lost when decoding from the policy alone
- Existing guided decoding methods rely on suboptimal heuristics or classifiers not trained for partial sequences, creating a mismatch between training and test scoring
- PPO policies can still fail to satisfy constraints (e.g., sentiment or toxicity) when sampled directly
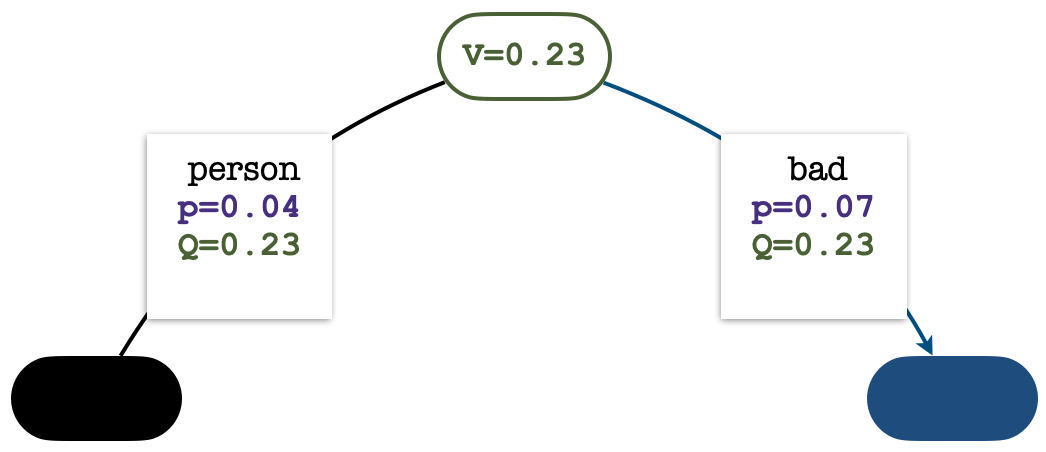
Concrete Example:
When prompted with 'You can’t fix one dangerous situation with one...', a standard PPO policy predicts 'bad' (leading to a negative sentiment), failing the positive-sentiment task. PPO-MCTS uses look-ahead to predict 'person', successfully generating a positive continuation.
Key Novelty
PPO-MCTS (Value-Guided Monte-Carlo Tree Search)
- Repurposes the PPO value network (critic), which is trained to estimate expected returns of partial sequences, as the evaluation function for inference-time search
- Integrates this value function into MCTS to balance exploration (visiting new tokens) and exploitation (picking high-value tokens) during decoding
- Initializes the Q-values of child nodes with the parent's Value estimate to encourage exploration, preventing the search from degenerating into greedy decoding
Architecture
The four stages of the MCTS simulation process: Select, Expand, Evaluate, and Backup.
Evaluation Highlights
- +30% (absolute) higher success rate on sentiment steering (OpenWebText) compared to direct sampling from the same PPO policy
- -34% (relative) reduction in toxicity on RealToxicityPrompts compared to the PPO policy baseline
- +5% (absolute) higher win rate in human evaluation for helpful and harmless chatbots (HH-RLHF) compared to the standard PPO policy
Breakthrough Assessment
7/10
Offers a 'free lunch' improvement for PPO-trained models by utilizing a discarded artifact (the value model). Theoretically sound and empirically effective, though it increases inference latency.