📝 Paper Summary
Policy Optimization
Variance Reduction
Proximal Policy Optimization (PPO)
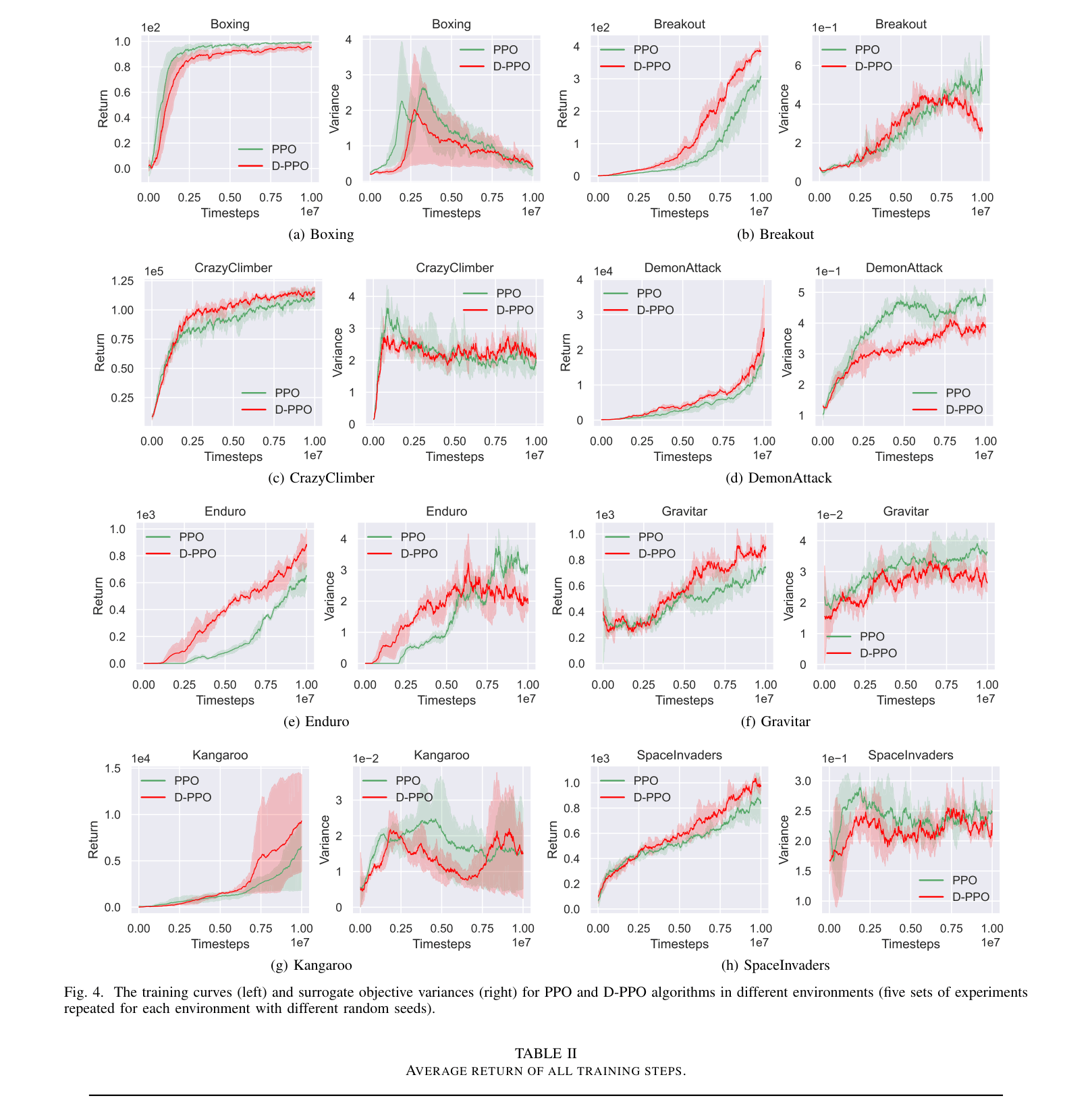
D-PPO reduces the excessive variance of the surrogate objective in policy optimization by selectively dropping training samples that contribute to high variance based on a derived upper bound.
Core Problem
Policy optimization algorithms like PPO and TRPO use importance sampling to reuse data, but this causes the variance of the surrogate objective to grow quadratically with the objective value, leading to training instability.
Why it matters:
- High variance in the surrogate objective destabilizes the policy update process, potentially leading to performance collapse or slow convergence.
- Existing variance reduction techniques like baselines (Actor-Critic) or GAE focus on gradient estimation variance, but lack systematic analysis of the surrogate objective's variance itself.
- Stable training is critical for Deep Reinforcement Learning in complex environments like Atari games where sample efficiency and robust convergence are required.
Concrete Example:
In the Breakout environment, standard PPO may experience spikes in the surrogate objective variance during training (e.g., around 7 million steps), which correlates with unstable returns or slower learning compared to a method that actively limits this variance.
Key Novelty
Dropout-PPO (D-PPO)
- Derives a theoretical upper bound for the variance of the importance-sampled surrogate objective, showing it grows quadratically with the objective's magnitude.
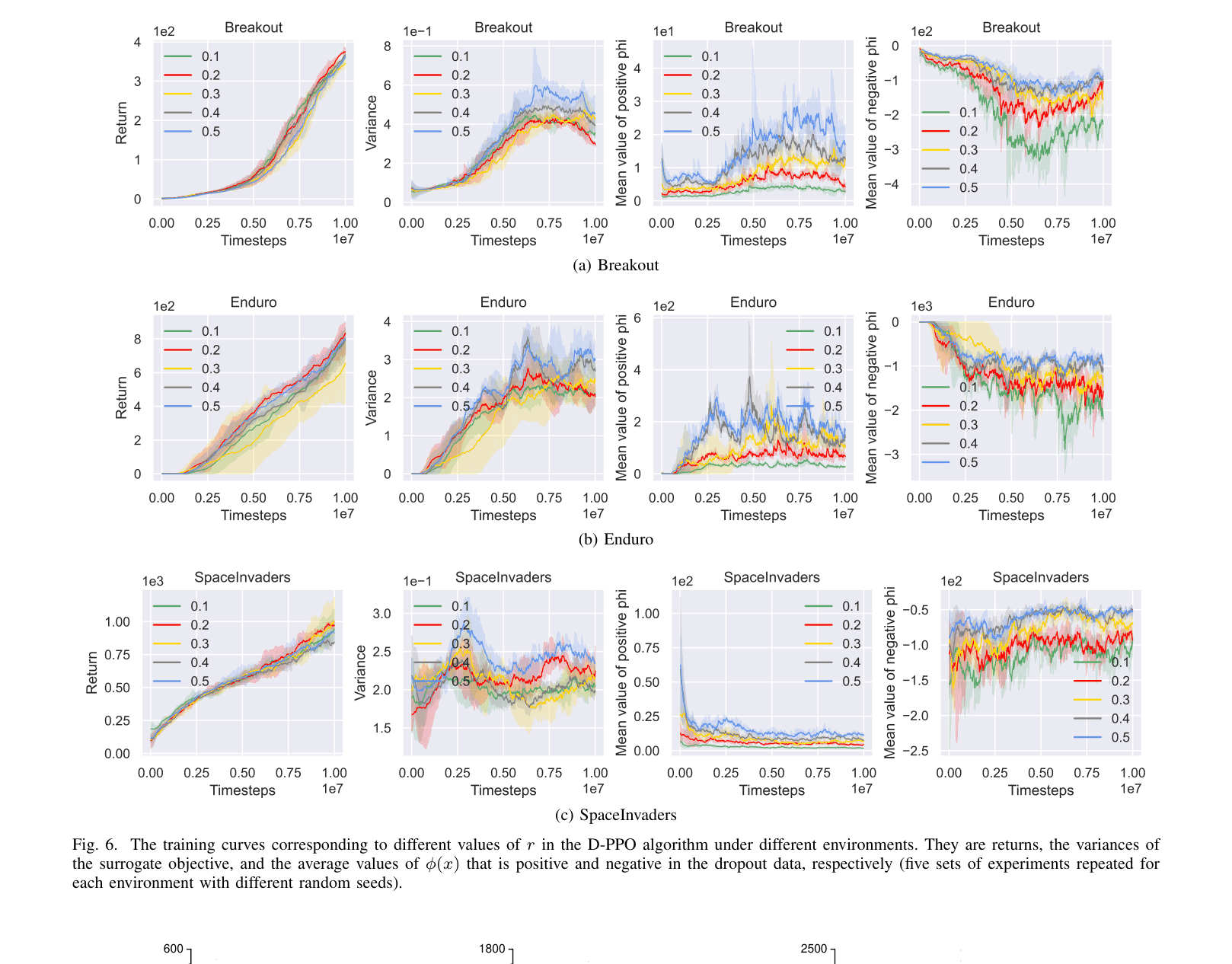
- Identifies that variance can be reduced by maximizing a specific term (correlation between samples), leading to a strategy of dropping samples with small values for this term.
- Implements a 'dropout' mechanism that discards a fixed ratio of training data (e.g., 20%) that contributes least to reducing the variance bound.
Architecture
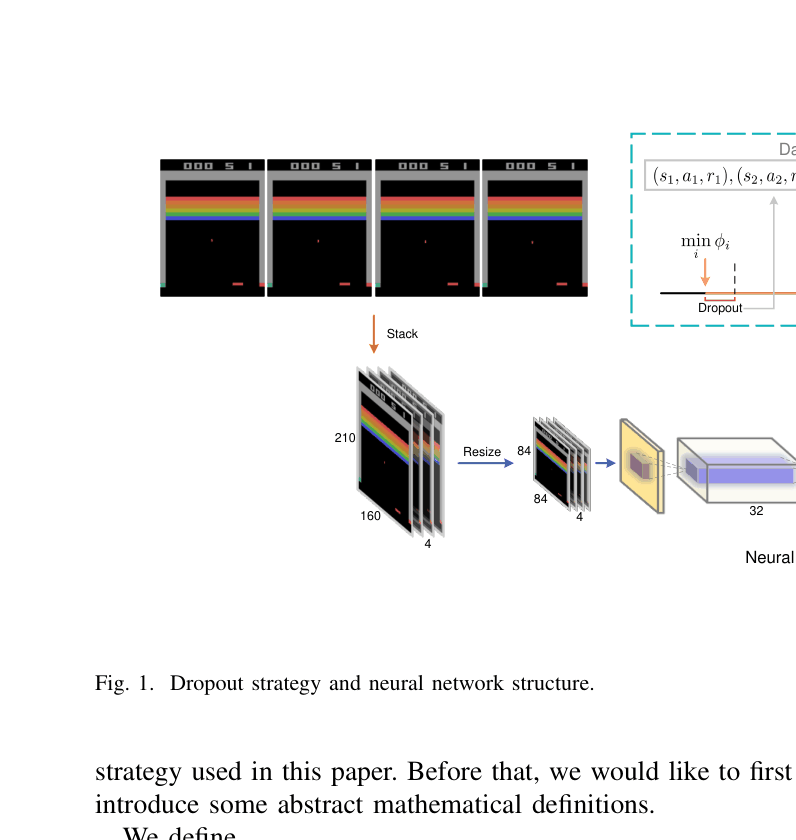
The neural network structure and the data flow incorporating the dropout strategy.
Evaluation Highlights
- +101.1% improvement in average return over PPO in the Enduro environment (194.5 vs 391.2).
- +70.1% improvement in average return over PPO in the Breakout environment (79.6 vs 135.5).
- Significantly reduced surrogate objective variance compared to PPO across multiple Atari environments (e.g., DemonAttack, Gravitar) throughout training.
Breakthrough Assessment
4/10
The paper provides a solid theoretical analysis of objective variance and a simple, effective fix (D-PPO). While the performance gains on Atari are strong, the method is an incremental modification to PPO rather than a paradigm shift.