📝 Paper Summary
LLM Alignment
Reinforcement Learning from Human Feedback (RLHF)
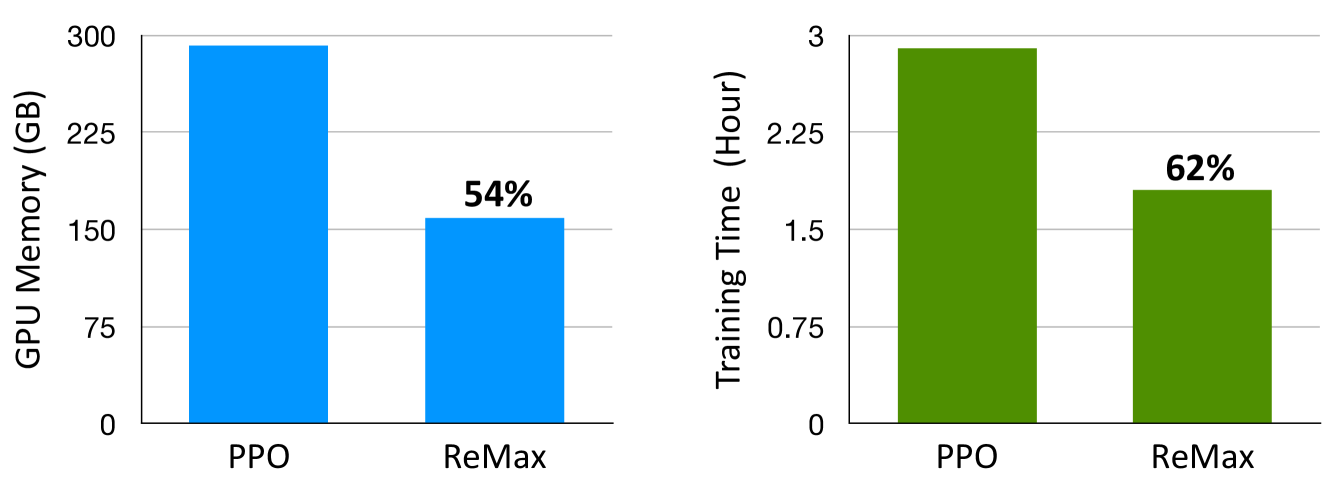
ReMax removes the resource-heavy value model from RLHF by leveraging the deterministic nature of language generation, achieving state-of-the-art performance with significantly lower memory usage than PPO.
Core Problem
The standard PPO algorithm used in RLHF is overly complex and computationally expensive for LLMs because it requires training a separate value model, doubling memory usage and complicating hyperparameter tuning.
Why it matters:
- Training the value model consumes ~46% of GPU memory (for a 7B model), often causing Out-Of-Memory errors on standard hardware
- PPO introduces sensitive hyperparameters (clipping, GAE coefficients) that are laborious to tune
- The computational burden makes RLHF inaccessible for researchers with limited GPU resources
Concrete Example:
When training a Llama-2-7B model on A800-80GB GPUs, standard PPO fails due to memory exhaustion unless slow optimizer offloading is used. In contrast, ReMax can train the same model natively on the GPU without offloading.
Key Novelty
ReMax (REINFORCE-based Maximization)
- Identifies that RLHF has deterministic transitions and trajectory-level rewards, rendering the complex credit assignment of PPO's value model unnecessary
- Replaces PPO's Actor-Critic architecture with a simpler REINFORCE-based gradient estimator
- Uses a variance reduction technique to stabilize training without requiring a learned value network
Architecture
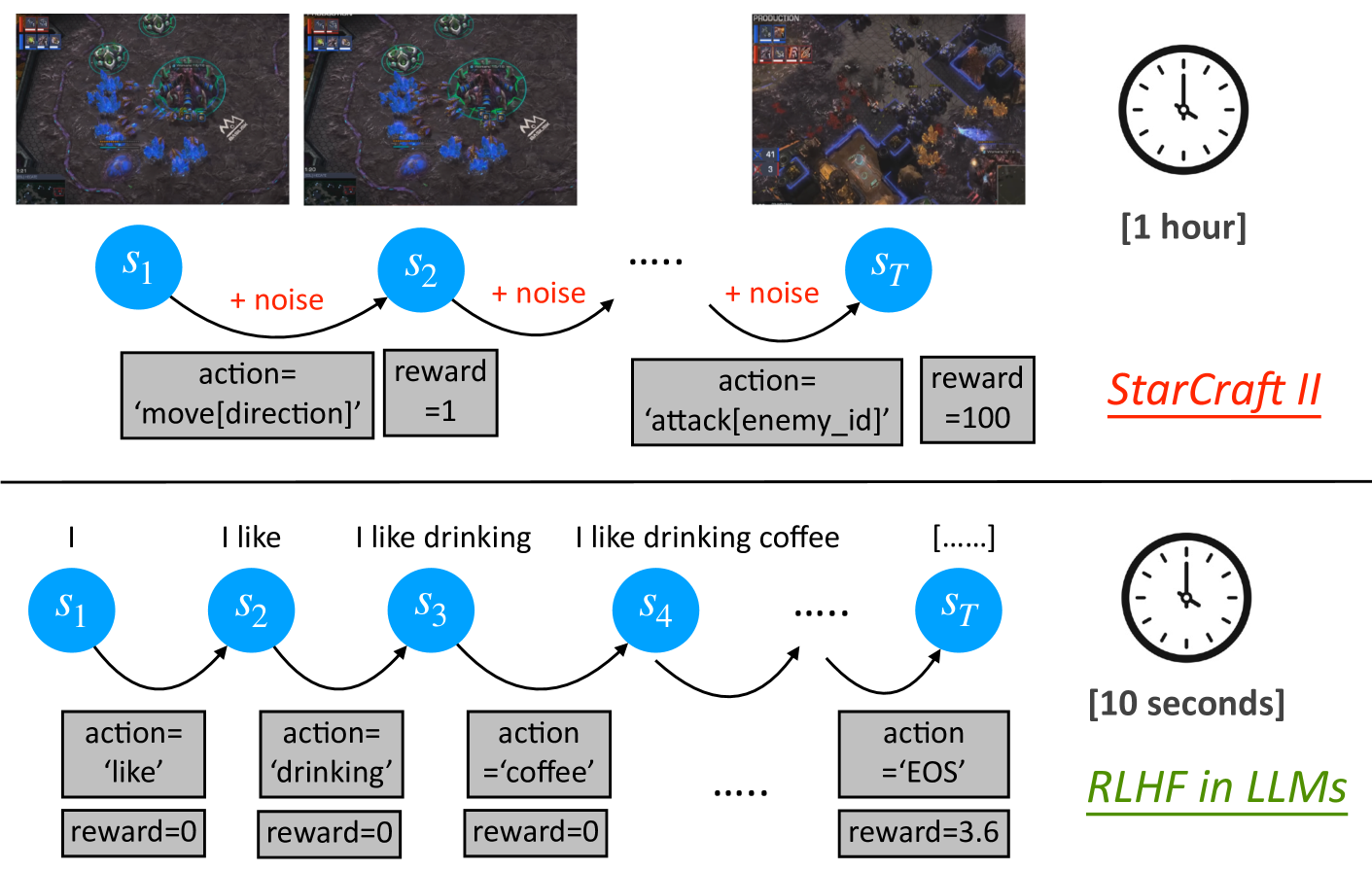
Conceptual illustration of RLHF properties: Fast Simulation, Deterministic Transitions, and Trajectory-level Rewards.
Evaluation Highlights
- Saves ~46% GPU memory compared to PPO when training a 7B model
- Achieves 94.78% win rate on AlpacaEval with Mistral-7B, setting a new SOTA for open-source 7B models
- Increases training speed by ~1.6x compared to PPO
Breakthrough Assessment
8/10
Significantly simplifies the standard RLHF pipeline by removing the value model while matching or exceeding SOTA performance and drastically reducing compute requirements.