📊 Experiments & Results
Evaluation Setup
Zero-shot classification (CLIP), Image Captioning, Visual Question Answering, and Targeted Attack Defense.
Benchmarks:
- ImageNet-1k / ImageNet-A / ObjectNet (Zero-shot Image Classification)
- COCO / Flickr30k (Image Captioning)
- VQAv2 / TextVQA / VizWiz (Visual Question Answering)
- POPE / MME-Perception (Hallucination & Perception Benchmark)
Metrics:
- Top-1 Accuracy (Clean & Robust)
- CIDEr (Captioning)
- VQA Accuracy
- Attack Success Rate (ASR)
- POPE F1 Score
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| CLIP Robustness: Δ-CLIP vastly outperforms post-hoc methods (TeCoA, FARE) on robustness while maintaining clean accuracy. | ||||
| ImageNet-1k | Robust Accuracy (APGD-100) | 46.1 | 66.5 | +20.4 |
| Stanford Cars | Robust Accuracy (APGD-100) | 11.1 | 86.8 | +75.7 |
| LLaVA Robustness: The double defense (Δ²-LLaVA) provides superior protection on downstream VQA and Captioning tasks. | ||||
| COCO Captioning | Robust CIDEr (Attack eps=4/255) | 58.2 | 89.5 | +31.3 |
| VQAv2 | Robust Accuracy (Attack eps=8/255) | 39.4 | 61.6 | +22.2 |
| Targeted Attacks: Δ²-LLaVA effectively neutralizes attempts to force specific malicious outputs. | ||||
| Targeted Attack (COCO subset) | Attack Success Rate (ASR, eps=16/255) | 51.7 | 3.3 | -48.4 |
| Hallucination & Helpfulness: Unlike prior robust models, Δ²-LLaVA preserves reasoning capabilities and reduces hallucinations. | ||||
| POPE | F1 Score (Hallucination) | 78.0 | 86.1 | +8.1 |
Experiment Figures
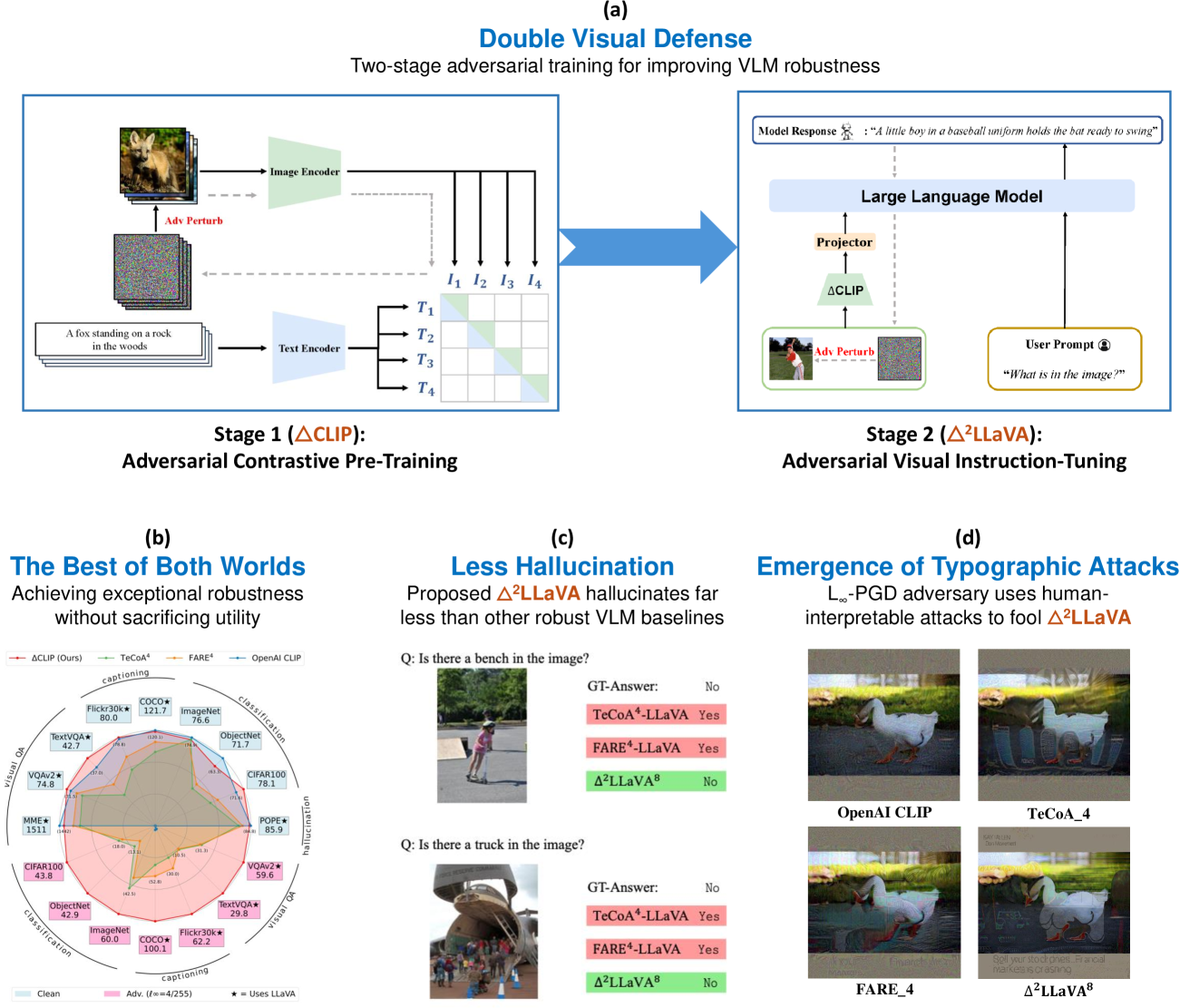
A radar chart comparing the relative robustness improvement of Δ-CLIP vs TeCoA and FARE across multiple datasets (Stanford Cars, EuroSAT, etc.).
Main Takeaways
- Adversarial pre-training from scratch (Δ-CLIP) is far superior to post-hoc adversarial fine-tuning for preserving zero-shot generalization capabilities.
- Post-hoc methods (TeCoA, FARE) severely overfit to ImageNet, causing massive robustness drops on out-of-distribution datasets (e.g., Stanford Cars).
- The 'Double Defense' strategy (adversarial pre-training + adversarial instruction tuning) yields the highest robustness against strong attacks (e.g., epsilon=16/255).
- Contrary to the common trade-off, this robustification method results in models that hallucinate *less* and reason *better* than prior robust baselines, matching standard clean model utility.