📝 Paper Summary
Morphology-Control Co-Design
Embodied Intelligence
Bi-level Optimization
Stackelberg PPO optimizes robot bodies and brains as a leader-follower game, using implicit differentiation to let morphology updates anticipate how the control policy will adapt.
Core Problem
Existing co-design methods typically optimize morphology assuming a fixed control policy, ignoring the fact that the controller will adapt to structural changes.
Why it matters:
- Optimizing morphology without accounting for controller adaptation leads to misalignment, where structural updates fail to elicit the optimal behavioral response
- Current approaches degrade performance by underestimating the true potential of evolving morphologies due to this lack of foresight
- Separating the optimization processes results in unstable and inefficient learning in the morphology space
Concrete Example:
A morphology optimizer might add legs to a robot (leader action) but fail to anticipate that the controller (follower) needs time to learn a new gait, leading the optimizer to discard the leg addition as 'low performance' before the controller adapts.
Key Novelty
Stackelberg PPO (Phase-Separated Stackelberg Markov Game for Co-Design)
- Models co-design as a Stackelberg game where the 'Leader' (morphology) moves first and anticipates the 'Follower' (control) best-response dynamics via implicit differentiation
- Introduces a surrogate objective derived via the log-derivative technique to handle the non-differentiable interface between discrete morphology edits and continuous control
- Adapts PPO's clipping mechanism to stabilize the high-variance updates typical of bi-level optimization with implicit gradients
Architecture
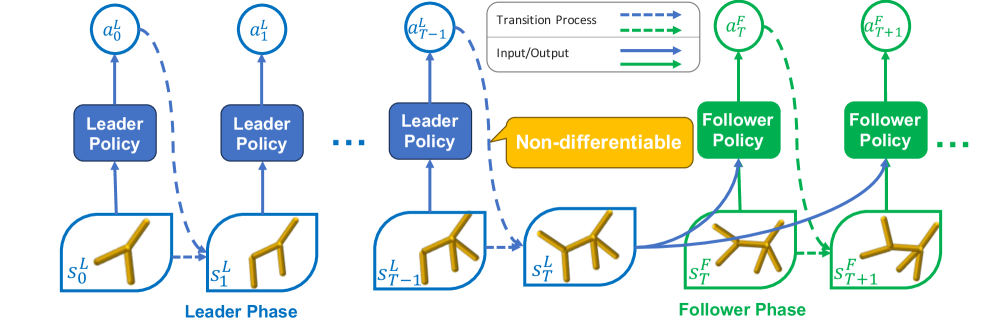
Illustration of the Phase-Separated Stackelberg Markov Game process for co-design
Evaluation Highlights
- Outperforms state-of-the-art baselines by 20.66% on average across diverse co-design tasks
- Achieves +32.02% performance improvement on complex 3D locomotion tasks compared to standard PPO-based co-design
- Demonstrates superior stability and convergence speed compared to single-level optimization approaches
Breakthrough Assessment
8/10
Significantly advances co-design by successfully applying implicit differentiation to a non-differentiable, phase-separated problem—a notoriously difficult setting in bi-level optimization.