📝 Paper Summary
LLM Alignment
Reinforcement Learning from Human Feedback (RLHF)
Direct Preference Optimization (DPO)
UNA unifies RLHF, DPO, and KTO by proving the optimal policy is induced by a generalized implicit reward function, allowing alignment via stable supervised regression between implicit and explicit rewards.
Core Problem
Existing alignment methods are fragmented: RLHF is unstable and memory-intensive; DPO is limited to pairwise data and ignores reward magnitude; KTO handles binary signals but lacks a unified framework for scalar scores.
Why it matters:
- RLHF's PPO (Proximal Policy Optimization) stage is notoriously unstable and requires managing four separate models in memory
- DPO improves stability but cannot utilize the rich, granular scalar information provided by reward models or fine-grained human scores
- Current methods cannot seamlessly switch between data types (pairwise, binary, scalar) or training modes (offline vs. online) within a single mathematical framework
Concrete Example:
In RLHF, an explicit reward model might assign a score of 0.9 to a high-quality response and 0.2 to a low-quality one. DPO ignores these specific values, only caring that 0.9 > 0.2. UNA utilizes the actual score differences to regress the policy, capturing the magnitude of preference.
Key Novelty
Generalized Implicit Reward Function
- Mathematically proves that the optimal policy in the RLHF objective is induced by a specific logarithmic ratio of the policy and reference model
- Transforms the alignment problem into a supervised learning task (e.g., MSE) that minimizes the difference between this 'implicit' reward (from the policy) and any 'explicit' reward (human or AI)
- Unifies data ingestion: treats pairwise, binary, and scalar feedback as variations of the same regression problem
Architecture
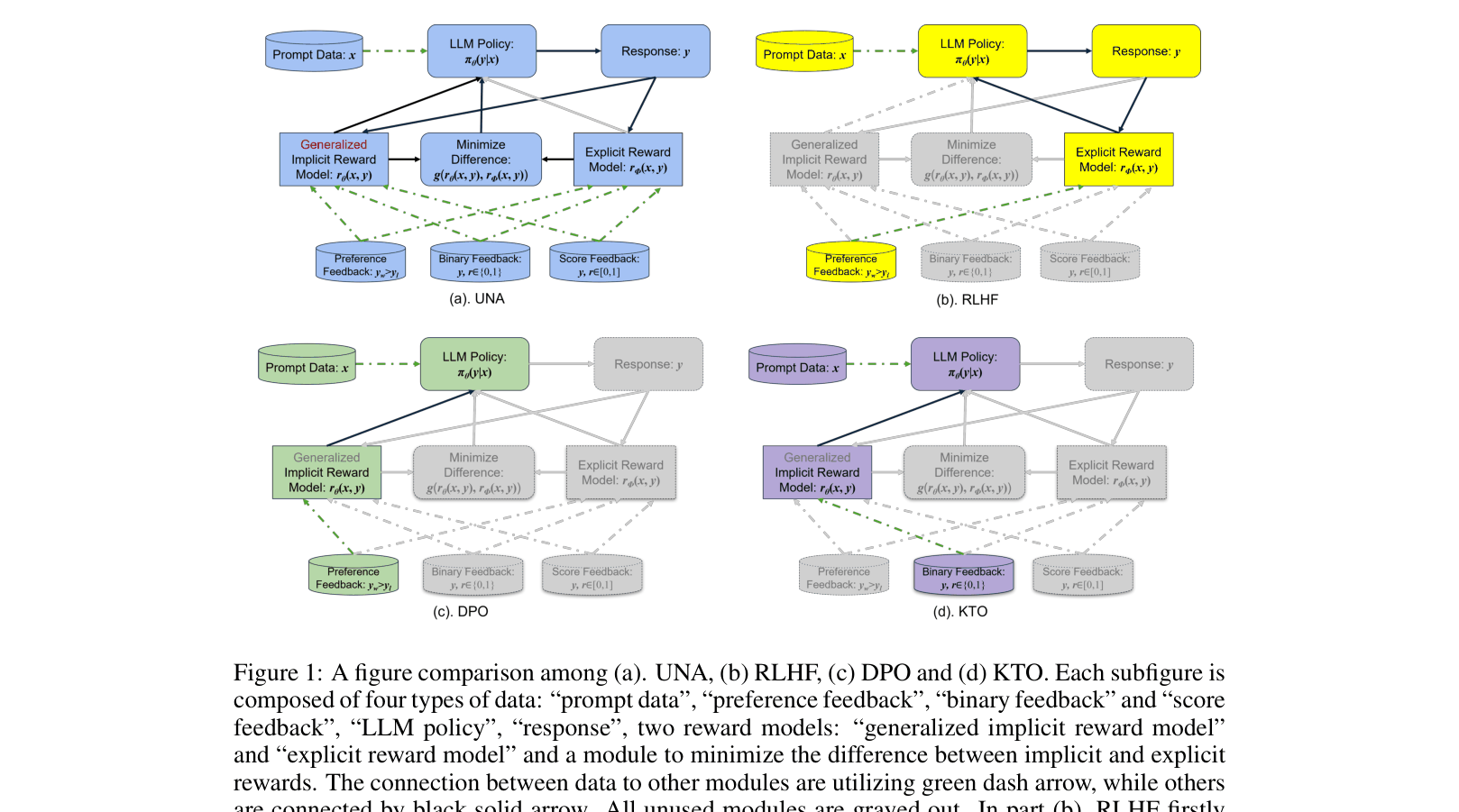
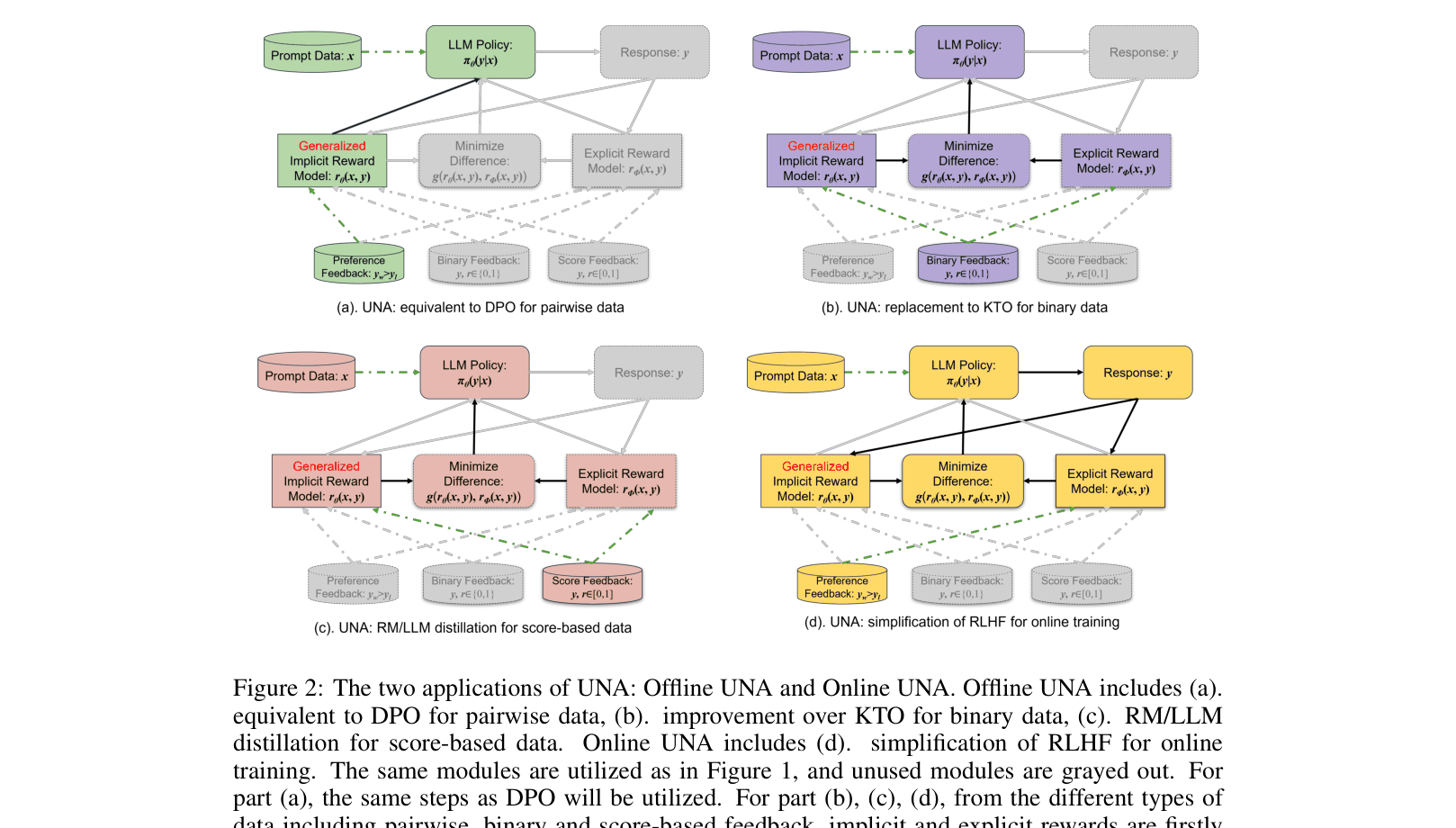
A conceptual comparison of UNA against RLHF, DPO, and KTO workflows, highlighting data flow and model components.
Evaluation Highlights
- +2.39 average score improvement on the new Open LLM Leaderboard using UNA-score (MSE) compared to DPO (28.53 vs 30.92)
- Reduces training time for online alignment by ~18% (6.5 hours vs 8 hours for RLHF) while removing the need for a Value model
- Achieves 6.78 on MT-Bench with UNA-binary, outperforming KTO (5.99) and DPO (6.1)
Breakthrough Assessment
8/10
Significantly simplifies the alignment landscape by unifying major paradigms (RLHF, DPO, KTO) under one mathematical derivation. The ability to use scalar rewards effectively in a DPO-like framework is a strong practical contribution.