📝 Paper Summary
On-policy Reinforcement Learning
Hybrid Policy Optimization
HP3O improves PPO sample efficiency by reusing recent trajectories via a FIFO buffer and guiding updates using the single best trajectory to mitigate distribution drift.
Core Problem
On-policy algorithms like PPO suffer from high sample complexity due to discarding data after updates, while off-policy methods suffer from data distribution drift and instability.
Why it matters:
- High sample complexity limits applicability in real-world continuous control (e.g., robotics) where data collection is expensive.
- Existing off-policy methods (SAC, TD3) can be unstable or computationally complex due to auxiliary variables required for variance reduction.
- Traditional replay buffers in off-policy learning introduce significant distribution drift when applied to on-policy objectives.
Concrete Example:
In a sparse reward environment, PPO may fail to improve because it discards a high-return trajectory after one update. If a traditional replay buffer is used to reuse it, the policy may diverge because the stored data comes from a very different, older policy distribution.
Key Novelty
Hybrid-Policy PPO (HP3O)
- Integrates a trajectory-based replay buffer into PPO but enforces a First-In-First-Out (FIFO) strategy to keep only recent data, minimizing distribution drift.
- Updates the policy using a hybrid batch composed of the single best trajectory (highest return) currently in the buffer plus randomly sampled trajectories.
- Introduces a 'best-trajectory baseline' (HP3O+) that calculates advantages based on improving upon the best historical return rather than the average value.
Architecture
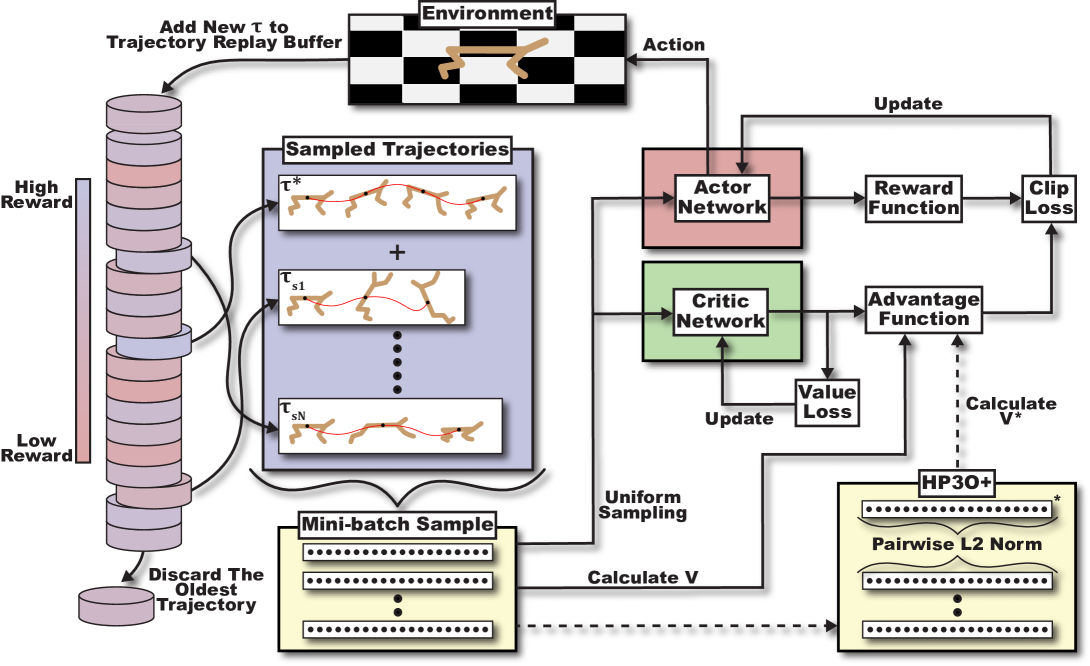
Conceptual diagram of HP3O showing the hybrid approach: synthesizing on-policy trajectory-wise updates with an off-policy trajectory replay buffer.
Breakthrough Assessment
5/10
Incremental but principled improvement over PPO. Addresses the known sample efficiency gap with a logical hybrid approach, though the core PPO mechanic remains largely unchanged.