📝 Paper Summary
Network Intrusion Detection Systems (NIDS)
Industrial Internet of Things (IIoT) Security
A framework combining TabTransformer for feature encoding with PPO-based reinforcement learning to robustly detect rare and imbalanced cyberattacks in industrial IoT networks.
Core Problem
Traditional deep learning models struggle with the heterogeneous tabular data and extreme class imbalance found in IIoT network traffic, often failing to detect rare but critical attacks.
Why it matters:
- IIoT systems face growing threats like DDoS and Man-in-the-Middle (MitM) attacks, where failure to detect can have physical consequences.
- Standard cross-entropy training favors frequent classes, leading to poor performance on rare attack types which are often the most dangerous.
- Existing few-shot methods often require complex meta-learning, while simpler tabular models (like decision trees) struggle with high-dimensional feature interactions.
Concrete Example:
In the TON_IoT dataset, the 'man-in-the-middle' (MitM) attack class has very few samples. A standard MLP trained with cross-entropy achieves a 0.00% F1-score on this class because the model is biased toward frequent normal traffic, completely missing the rare attack.
Key Novelty
TabTransformer-PPO Hybrid Framework
- Replaces the standard supervised classification loss with a Reinforcement Learning policy gradient approach (PPO), treating classification as a decision-making process with rewards.
- Uses a TabTransformer encoder to capture complex interactions between categorical and numerical features in tabular network logs, providing a rich state representation for the RL agent.
- Introduces a composite reward function that specifically targets imbalance by rewarding correct classification, penalizing low confidence, and punishing repetitive mistakes.
Architecture
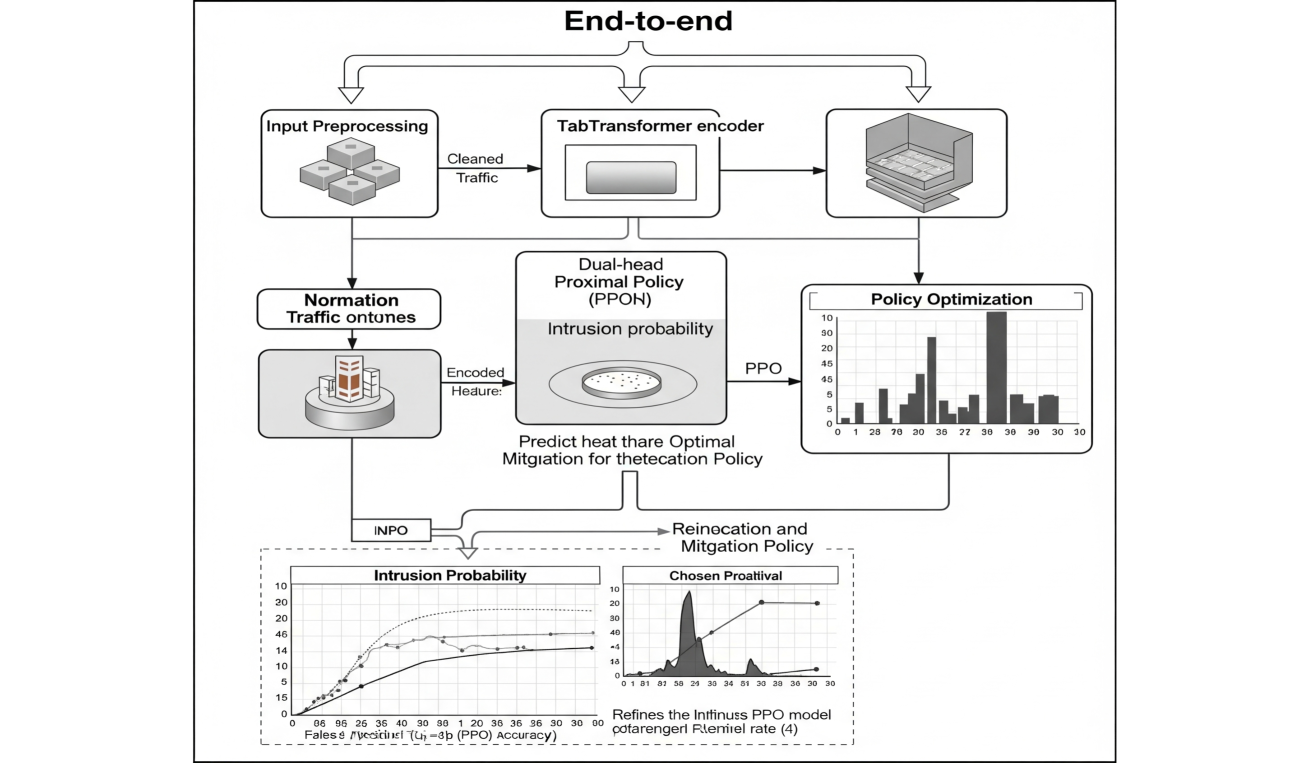
The end-to-end pipeline: Preprocessing → TabTransformer Encoder → Dual Head (Policy/Value) → PPO Optimization Loop.
Evaluation Highlights
- Achieves 88.79% F1-score on the extremely rare 'mitm' (Man-in-the-Middle) attack class, compared to 0.00% for an MLP baseline.
- Attains an overall Macro F1-score of 97.73% on the TON_IoT benchmark, demonstrating strong generalization across diverse attack types.
- Outperforms standard supervised baselines in robustness, maintaining high recall on minority classes without sacrificing performance on frequent classes.
Breakthrough Assessment
7/10
Strong application of RL to a traditionally supervised tabular problem, yielding impressive gains on rare classes. While the architectural components (TabTransformer, PPO) are existing, their integration for imbalanced IDS is a solid contribution.