📊 Experiments & Results
Evaluation Setup
Sentiment generation task using IMDb movie reviews
Benchmarks:
- IMDb Sentiment Analysis (Text Generation / Sentiment Classification)
Metrics:
- Average Sentiment Score (0.0 to 1.0, higher is more positive)
- Cosine Similarity (of weights)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| IMDb Sentiment | Average Sentiment Score | 0.27 | 0.80 | +0.53 |
| IMDb Sentiment | Average Sentiment Score | 0.80 | 0.43 | -0.37 |
| Internal Analysis | Cosine Similarity | 1.00 | 0.9998 | -0.0002 |
Experiment Figures
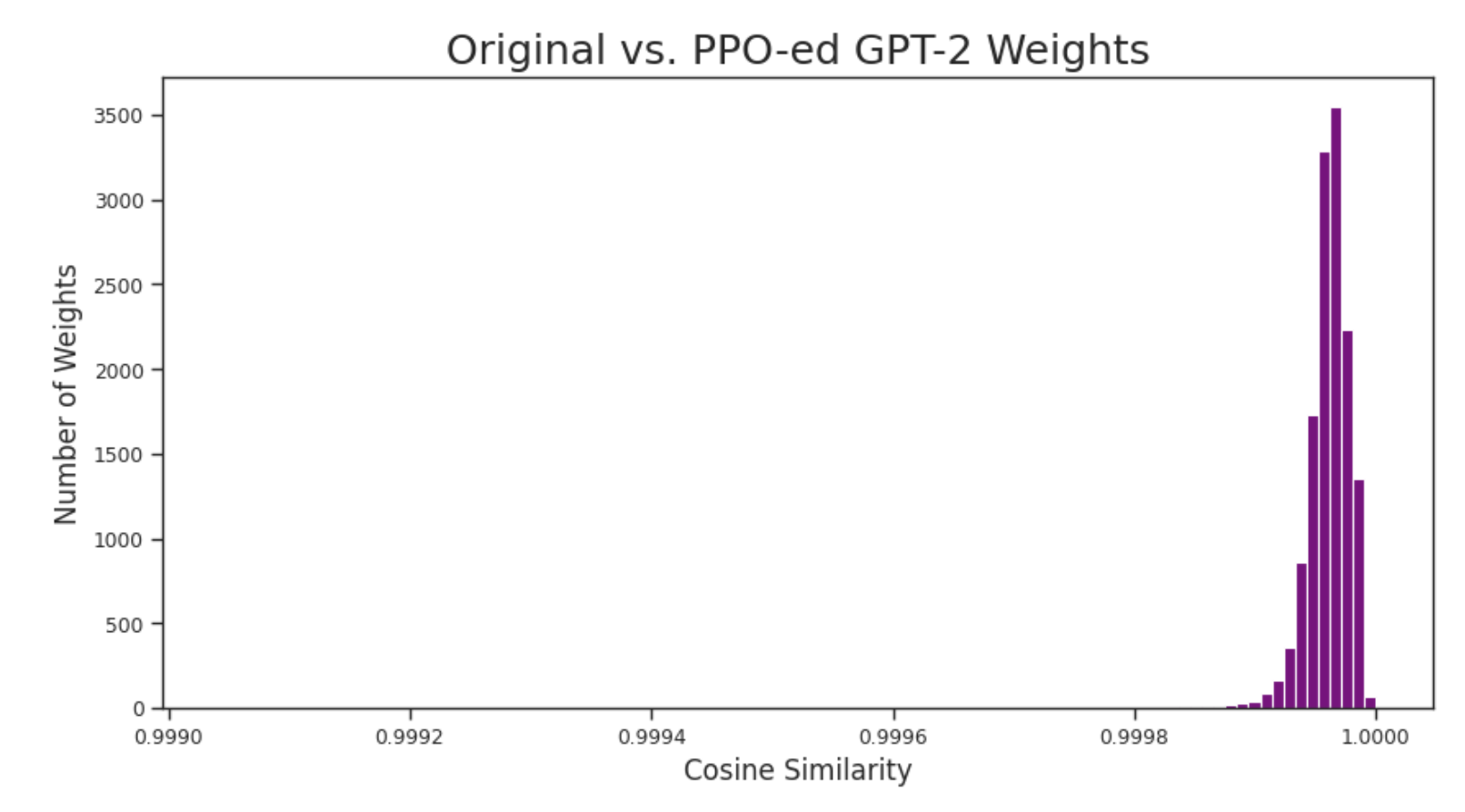
Histogram of cosine similarities between original and PPO-ed weights
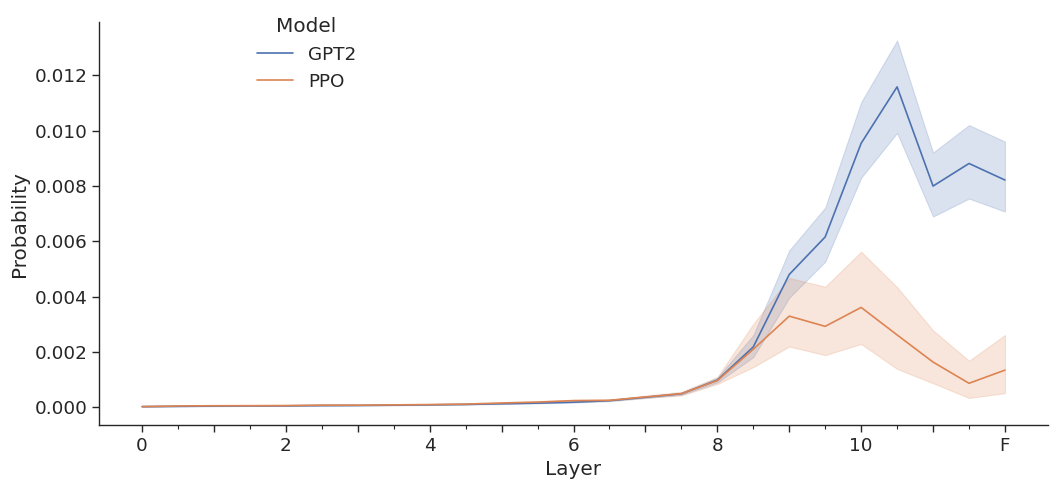
Delta in activations for top-k negative value vectors before and after PPO
Main Takeaways
- PPO functions by learning a 'wrapper' or offset that suppresses undesirable activations rather than unlearning the underlying concepts.
- Negative concepts remain stored in the model's weights (specifically value vectors in layers 6-9) even after successful alignment.
- It is possible to mechanistically 'hack' an aligned model by identifying and amplifying these dormant negative weights, forcing the model to ignore its alignment.
- Attempts to fix this by directly penalizing negative weights in the reward function caused model instability, highlighting the difficulty of 'unlearning' via RL.