📝 Paper Summary
Reinforcement Learning Theory
Policy Optimization
This paper establishes the first global convergence guarantee for PPO-Clip with neural function approximation by reinterpreting the clipped objective as a hinge loss and decoupling policy search from parameterization.
Core Problem
While PPO-Clip is one of the most popular and empirically successful deep RL algorithms, it lacks theoretical substantiation for its global convergence, particularly under neural function approximation.
Why it matters:
- PPO-Clip is widely used in applications like robotics and gaming (e.g., OpenAI Five), yet its theoretical properties were largely unknown compared to PPO-KL or TRPO
- Understanding the clipping mechanism is crucial for explaining why the algorithm is robust to hyperparameter changes and advantage estimation errors
Concrete Example:
Previous theoretical works established convergence for PPO-KL (using KL divergence penalty) and TRPO, but PPO-Clip's heuristic of 'clipping probability ratios' had no proven convergence rate, leaving a gap between theory and practice.
Key Novelty
Hinge-Loss Interpretation & EMDA-Based Policy Search
- Reformulates the PPO-Clip objective by showing its gradient is equivalent to a hinge loss derivative, allowing the use of convex optimization tools
- Decouples the difficult problem of neural policy optimization into two steps: (1) finding an improved target policy using Entropic Mirror Descent (EMDA), and (2) fitting a neural network to this target via regression
- Demonstrates that the clipping range parameter affects only the constant factor of the convergence speed, not the asymptotic rate itself
Architecture
Pseudocode for the Neural PPO-Clip algorithm showing the interplay between TD learning, EMDA, and SGD.
Evaluation Highlights
- Proves Neural PPO-Clip achieves an O(1/√T) min-iterate convergence rate, matching the standard rate for non-convex optimization
- Proves asymptotic convergence for Tabular PPO-Clip with direct parameterization using Entropic Mirror Descent
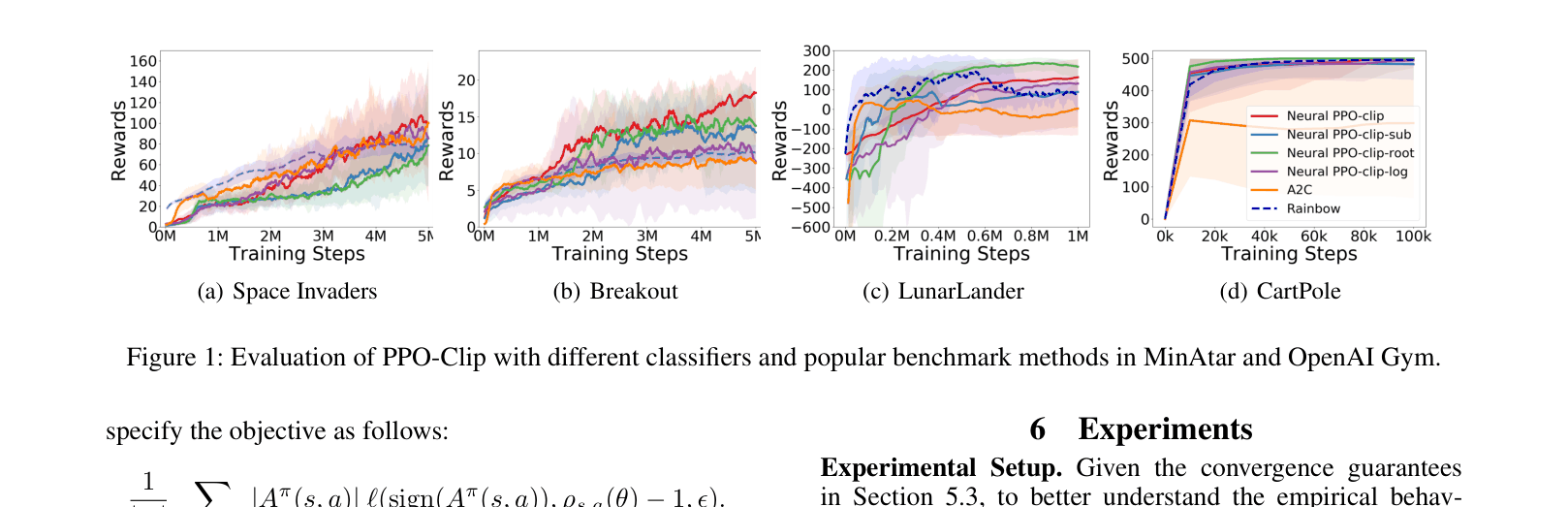
- Empirically demonstrates that the generalized hinge-loss PPO variants achieve performance comparable to or better than A2C and Rainbow on MinAtar and OpenAI Gym benchmarks
Breakthrough Assessment
8/10
Significant theoretical contribution filling a major gap in RL literature. It provides the first convergence proof for the widely used PPO-Clip algorithm with neural networks, offering deep insights into why clipping works.